知识储备
并发和并行
单核上,CPU时间片轮转,多个线程轮流执行。物理上是串行执行的,但是由于每个线程占用的CPU时间片非常短(比如10ms),宏观上看就像是多个线程在共同执行,这样的场景称作并发(concurrent)。
在多核或者多CPU上,多个线程在同一时刻执行,这样的场景才是真正的并行(parallel)。
两种密集型程序
多线程程序一定好吗?不一定,要看具体的应用场景。
- IO密集型:程序里面指令的执行,涉及IO操作较多,比如设备、文件、网络操作(等待客户端的连接),可能会把程序阻塞。如果CPU时间片再分配给这种线程,相当于浪费了CPU资源。
- CPU密集型:程序里面的指令都是做计算用的,不会阻塞。
- 多核情况下
- IO密集型和CPU密集型虽然对并行计算有不同的需求,IO密集型更适合设计成多线程程序。但是在多核情况下两种密集型程序都是有必要用多线程来处理的。
- 线程进行调度时,内核中有这样两个队列:runnable,就绪的或正在调度的队列。如果因IO操作有线程阻塞了,则将会进入阻塞队列,blocking queue。
- 单核情况下
- IO密集型的程序依然适合设计为多线程程序。
- CPU密集型程序不再适合!这就相当于只有一个计算器,却让多个人分段算。线程的调度有额外的花费:线程的上下文切换。CPU寄存器信息会保存在线程栈上,下次还要再恢复到CPU中,实属麻烦。
线程的代价
为了完成任务,创建很多线程可以吗?线程越多越好吗?
- 线程的创建和销毁都是非常“重”的操作,需要进入内核态。在执行任务的过程中,没有集中资源去干正事,而是去花费很大力度创建/销毁?
- 需要给线程创建
PCB(task_struct)、线程的内核栈、页目录、页表
- 描述地址空间相应的数据结构:
vm_area_struct
- 内核创建完后,还要返回用户态
- 线程执行完业务,还要销毁线程,又要切换一次
- 线程栈本身占用大量内存,每一个线程都需要线程栈,栈几乎都被占用完了,还怎么做事情?
- 32位地址空间,共4G,用户空间有3G。
- 线程共享进程的地址空间。
- 可在linux下执行
ulimt -a命令观察stack size默认栈大小,为8192字节即8M。
- 3∗1024M=3072M,3072M/8M=384个。这说明32位环境下,最多创建384个线程。
- 线程的上下文切换要占用大量时间
- 线程过多,线程的调度是需要进行上下文切换的,上下文切换花费CPU时间也特别多,CPU的利用率就不高了。
- 大量线程同时唤醒会使系统经常出现锯齿状负载或者瞬间负载量很大导致宕机
- 如果在某一时刻,大量的IO操作准备好了,那么一时间线程是来不及处理的。
线程同步
线程互斥
某段代码能不能多线程环境下执行?看这段代码是否存在竞态条件,即有无临界区代码段。(代码片段在多线程环境下执行,随着线程的调度顺序不同而得到不同的执行结果)。如果有,则要通过线程同步来保证它的原子操作。
如果在多线程环境下不存在竞态条件,则称之为可重入的。
互斥锁
- lock
try_locklock_guardunique_lock
atomic原子类型
- CAS操作(无锁机制)
- 无锁队列、无锁链表、无锁数组
- 实际上使用的是轻量级、效率高的锁,不是没用锁。
线程通信
GDB调试C++11多线程死锁
条件变量
信号量
看作资源计数没有限制的mutex互斥锁。mutex互斥锁的资源计数只能是0或者1。
区别
- 二元信号量和互斥锁的区别
- mutex只能是哪个线程获取锁,由哪个线程释放锁。
sem.wait()和sem.post()则可以处在不同的线程中调用。
线程池
线程池的优势:
服务进程启动之初,事先创建好线程池里面的线程,当业务到来需要分配线程时直接从线程池中获取一个空闲线程执行task任务即可,task执行完成之后把线程归还到线程池中继续给后续task提供服务,而不用释放线程。
项目介绍
本项目所实现的线程池和对象池、内存池、STL库的意义一样,只能称作一个库,而不能作为一个独立运行的中间件,必须镶嵌在应用程序中。最终项目表现形式为一种提供给他人的动态库,比如用到了mysql.h头文件,libmysqlclient.so动态库。动态库需要编译出来。
使用方式
如果你想在应用程序中或者代码中使用本项目的线程池,你可以
- 直接
ThreadPool pool;定义一个pool对象;
- 而后则可以调用
pool.sexMode(fixed(default) | cached);接口设置线程池的运行模式,默认为固定模式。
- 然后
pool.start();启动线程池。start不会阻塞。
启动线程池意味着线程池开始创建若干线程,就绪,等待任务过来执行任务。
调用方只要按以下形式调用API即可:Result result = pool.submitTask(concreteTask);
调用方无需关心内部操作,包括线程分配、执行过程。
有时调用方需要获取任务执行的结果,可用T res = result.get().Cast<T>();获得任务结果。任务结果的返回值是任意类型,具体类型T由用户指出。(此处用到了C++17中的Any类型)
线程池的设计
类成员
首先说一说抽象出的类:线程池类、线程池中的线程类。
- 既然是线程池,就要有一个存放线程的容器
- 我们最好能实时监控线程池中线程的数量、以及上限阈值,避免线程数量走向极端从而影响性能(线程数量不是越多越好,坏处:1、线程栈空间冗余;2、上下文切换过程时间多于执行操作)
- 还要有一个存放待完成任务的容器,即任务队列
- 考不考虑线程安全问题?必须考虑,外层用户提交任务要放数据,下层线程执行任务要取数据。
- 任务不能堆积过多。对于任务队列,也要有一个上限阈值。
通用化的实现 - Task设计 - 继承多态思想
任务类型需要达到通用性,所以要用到继承、多态的思想。用基类指针可以指向各种各样的派生类对象。
所以需要设计一个抽象类Task。内部提供一个纯虚函数virtual void run() = 0。如果要设计特定的任务,则继承(实现)之,重写run函数即可。
线程通信的保证 - mtx+cv
因为涉及到放任务、取任务,所以很明显是个生产者消费者模型。
必然用到互斥锁+条件变量,从而对任务队列进行互斥保护、达到正确的线程通信。
线程池的模式
- fixed模式
- 线程池里面的线程个数是固定不变的,一般是ThreadPool创建时根据当前机器的CPU核心数量进行指定。
- cached模式
- 线程池里面的线程个数是可动态增长的,根据任务的数量动态地增加线程的数量,但是会设置一个线程数量的阈值。任务处理完成后,如果动态增长的线程空闲60s而没有其他任务待处理,那么就关闭线程,保持池中线程的最初数量。
代码形式
1
2
3
4
5
6
| int main()
{
ThreadPool pool;
pool.setMode(fixed(default) | cached);
pool.start();
}
|
提交任务API
1
2
| Result result = pool.submitTask(concreteTask);
result.get().Cast<T>();
|
线程池类(ThreadPool)
线程池,不光要管理线程,而且要集成一个任务队列。要对外提供提交任务的接口。
其中的线程去取任务,做,然后返回任务结果。(这是线程类里的事情)
管理的线程,用 vector 管理。
管理的任务,用 queue 管理。任务队列要保证线程安全。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| enum class PoolMode
{
MODE_FIXED,
MODE_CACHED,
};
class ThreadPool
{
public:
ThreadPool();
~ThreadPool();
void setMode(PoolMode mode);
void setInitThreadSize(int size);
void setTaskQueMaxThreshHold(int threshHold);
void start();
void submitTask(std::shared_ptr<Task> task);
private:
PoolMode m_poolMode;
std::vector<Thread*> m_threads;
int m_initThreadSize;
std::queue<std::shared_ptr<Task>> m_taskQueue;
std::atomic_int m_taskNum;
int m_taskQueMaxThreshHold;
std::mutex m_taskQueMtx;
std::condition_variable m_taskQueNotFull;
std::condition_variable m_taskQueNotEmpty;
private:
ThreadPool(const ThreadPool &) = delete;
ThreadPool& operator=(const ThreadPool &) = delete;
};
|
ThreadPool构造、析构
1
2
3
4
5
6
7
8
9
10
11
12
13
|
ThreadPool::ThreadPool()
: m_initThreadSize(4),
m_taskNum(0),
m_taskQueMaxThreshHold(TASK_MAX_THRESHHOLD),
m_poolMode(PoolMode::MODE_FIXED)
{
}
ThreadPool::~ThreadPool()
{
}
|
设置参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
void ThreadPool::setMode(PoolMode mode)
{
m_poolMode = mode;
}
void ThreadPool::setInitThreadSize(int size)
{
m_initThreadSize = size;
}
void ThreadPool::setTaskQueMaxThreshHold(int threshHold)
{
m_taskQueMaxThreshHold = threshHold;
}
|
启动线程池
1
2
|
void ThreadPool::start(int initThreadSize);
|
给线程池提交任务
1
2
|
void ThreadPool::submitTask(std::shared_ptr<Task> task);
|
Thread类
线程函数定义在哪个位置呢?
- 思考:线程函数定义在哪个位置呢?
- 如果写在Thread类中,那么定义在 ThreadPool 的变量则不容易被函数所访问。
- 定义为全局函数呢?线程池里的变量都是私有的,也不易访问。
- 结论:OOP的手法,写在ThreadPool中。
1
2
3
4
5
6
7
|
class ThreadPool
{
private:
void threadFunc();
};
|
怎么把线程函数扔给Thread对象
- 线程对象是在线程池里构建的,线程启动执行也是在线程池里做的,
- 那么创建 thread 线程对象时需要把线程函数给到 thread 线程对象。怎么把函数扔给对象?怎么解决这个技术问题?
- 引入
<functional>,用std::bind()把函数对象绑定。在线程池 start 时,构造 thread 时传入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| void ThreadPool::start(int initThreadSize)
{
m_initThreadSize = initThreadSize;
for(int i = 0; i < m_initThreadSize; ++i)
{
m_threads.emplace_back(
new Thread(std::bind(&ThreadPool::threadFunc, this))
);
}
for(int i = 0; i < m_initThreadSize; ++i)
{
m_threads[i]->start();
}
}
|
头文件
由上述 Thread 类构造时对函数对象的处理,可以得到 Thread 类的大致属性需求、构造参数。
1
2
3
4
5
6
7
8
9
10
11
| class Thread
{
public:
using ThreadFunc = std::function<void()>;
Thread(ThreadFunc func);
~Thread();
void start();
private:
ThreadFunc m_func;
};
|
start 函数(创建线程后,分离线程)
- start 函数 - 启动线程,创建一个线程来执行一个线程函数
- 需要注意:出了start函数作用域之后线程对象会析构,但是线程函数不能消失,他还要去消费任务队列上的任务。所以线程对象需要设置为分离线程,否则程序会挂掉。
- 分离的效果就是:线程对象和它所启动的线程(实质的线程)分离开了。独立存在,互不关心对方的生命期。
1
2
3
4
5
6
7
8
|
#include<thread>
void Thread::start()
{
std::thread t(m_func);
t.detach();
}
|
简单测试
- 简单测试,默认启动 4 个线程。启动后在不同的线程分别执行 threadFunc 函数。
- 注意:创建的线程分离之后,执行完毕后会自动回收。但是可能存在主线程启动后看不到打印结果的情况,那是因为主线程结束地太快,导致没能看到(实际中的服务器主线程不会很快结束,而是保持)。为了看到执行结果,可以睡眠一段时间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| void ThreadPool::threadFunc()
{
std::cout << "begin threadFunc tid:"
<< std::this_thread::get_id() << std::endl;
std::cout << "end threadFunc"
<< std::this_thread::get_id() << std::endl;
}
#include"threadpool.h"
#include<iostream>
#include<chrono>
#include<thread>
int main()
{
ThreadPool pool;
pool.start();
std::this_thread::sleep_for(std::chrono::seconds(5));
}
|
智能指针解决避免手动释放
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| void ThreadPool::start(int initThreadSize)
{
m_initThreadSize = initThreadSize;
for(int i = 0; i < m_initThreadSize; ++i)
{
auto ptr = std::make_unique<Thread>(
std::bind(&ThreadPool::threadFunc, this)
);
m_threads.emplace_back(ptr);
}
for(int i = 0; i < m_initThreadSize; ++i)
{
m_threads[i]->start();
}
}
|
但是这样会出现编译不过的问题,为什么呢?因为报错发现unique_ptr的拷贝构造已经删除,这是唯一性智能指针的语义决定的。而移动构造没有删除,意味可以用右值进行资源转移,所以我们需要在ptr前加std::move。
1
| m_threads.emplace_back(std::move(ptr));
|
submitTask
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
void ThreadPool::submitTask(std::shared_ptr<Task> sp)
{
std::unique_lock<std::mutex> lock(m_taskQueMtx);
m_taskQueNotFull.wait(
lock,
[&]()->bool {
return m_taskQueue.size() < m_taskQueMaxThreshHold;
}
);
m_taskQueue.emplace(sp);
++m_taskNum;
m_taskQueNotEmpty.notify_all();
}
|
服务降级(wait_for(time))
为了性能更加优化,我们限制用户提交任务的最长阻塞时间是1s,如果提交任务超过了 1s 说明目前线程池的任务队列压力比较大,防止短时间内积压很多任务,则规定为提交任务失败,返回。称为服务降级。
需要用到wait的两个延伸,wait_for(time),wait_until(endtime)。返回值为bool值,false表示到时间后条件依然没满足。
以下说的是:如果等了超过 1 秒,说明满的状态已经超过了 1 秒,wait_for返回 false ,if 条件成立,提交失败。
1
2
3
4
5
6
7
8
9
10
| if(!m_taskQueNotFull.wait_for(
lock,
std::chrono::seconds(1),
[&]()->bool {
return taskQue_.size() < (size_t)taskQueMaxThreshHold_;
}))
{
std::cerr<<"task queue is full, submit out of time failed."<<endl;
return;
}
|
ThreadFunc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| void ThreadPool::threadFunc()
{
for(;;)
{
std::shared_ptr<Task> task;
{
std::unique_lock<std::mutex> lock(m_taskQueMtx);
std::cout << "tid:" << std::this_thread::get_id()
<< "尝试获取任务..." << std::endl;
m_taskQueNotEmpty.wait(
lock,
[&]()->bool {
return m_taskQueue.size() > 0;
}
);
std::cout << "tid:" << std::this_thread::get_id()
<< "获取任务成功..." << std::endl;
task = m_taskQueue.front();
m_taskQueue.pop();
--m_taskNum;
if (m_taskQueue.size() > 0)
{
m_taskQueNotEmpty.notify_all();
}
m_taskQueNotFull.notify_one();
}
if(task != nullptr)
task->run();
}
}
|
测试1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| class MyTask : public Task
{
public:
void run()
{
std::cout << "tid:" << std::this_thread::get_id()
<< "begin!" << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(2));
std::cout << "tid:" << std::this_thread::get_id()
<< "end!" << std::endl;
}
};
-------------------------------------------------------------------
test example:
int main()
{
ThreadPool pool;
pool.start(4);
pool.submitTask(std::make_shared<MyTask>());
pool.submitTask(std::make_shared<MyTask>());
pool.submitTask(std::make_shared<MyTask>());
getchar();
}
|
线程执行的返回值(future和packaged_task的实现原理)
比如,计算1到30000的和。线程1计算1到10000,2计算10001到20000,3计算20001到30000。
主线程给每一个线程分配计算的区间,并等待他们算完之后返回结果,合并最终的结果即可。
但是,怎么能拿到线程的返回值呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| class MyTask : public Task
{
public:
MyTask(int begin, int end)
: begin_(begin), end_(end)
{
}
void run()
{
std::cout << "tid:" << std::this_thread::get_id()
<< "begin!" << std::endl;
int sum = 0;
for(int i = begin_; i <= end_; ++i)
{
sum += i;
}
std::cout << "tid:" << std::this_thread::get_id()
<< "end!" << std::endl;
return sum;
}
};
|
- 问题1:怎么设计run函数的返回值,可以表示任意的类型?
- 问题2:如何设计这里的Result机制?
1
2
3
4
5
6
| Result res1 = pool.submitTask(std::make_shared<MyTask>(1, 10000));
Result res2 = pool.submitTask(std::make_shared<MyTask>(10001, 20000));
Result res3 = pool.submitTask(std::make_shared<MyTask>(20001, 30000));
res1.get();
res2.get();
res3.get();
|
Any类型 - 按需返回具体类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| class Any
{
public:
Any() = default;
~Any() = default;
Any(const Any&) = delete;
Any& operator=(const Any&) = delete;
Any(Any &&) = default;
Any& operator=(Any &&) = default;
template<typename T>
Any(T data) : base_(std::make_unique<Derived<T>>(data))
{}
template<typename T>
T cast_()
{
Derive<T>* pd = dynamic_cast<Derive<T>*>(base_.get());
if(pd == nullptr)
{
throw "type is unmatch!";
}
return pd->data_;
}
private:
class Base
{
public:
virtual ~Base() = default;
};
template<typename T>
class Derived : public Base
{
public:
Derived(T data) : data_(data)
{}
private:
T data_;
};
private:
std::unique_ptr<Base> base_;
};
int main()
{
ThreadPool pool;
pool.start(4);
Result res = pool.submitTask(std::make_shared<MyTask>(1, 10000));
int sum = res.get().cast_<int>();
}
|
如此一来:
res调用get,等待 task 执行完毕,get()就能返回一个Any。这个 Any 的模板参数指明了里面存放的数据是 int 型, Any 对象调用其 cast_, 取出了里面存放的数据。(通过dynamic_cast<Derive<int>*>)如果类型不匹配,则抛出异常。
自实现信号量类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| class Semaphore
{
public:
Semaphore(int limit = 0)
: resLimit_(limit)
{
}
~Semaphore() = default;
void wait()
{
std::unique_lock<std::mutex> lock(mtx_);
cond_.wait(lock, [&]()->bool {return resLimit_ > 0;});
--resLimit_;
}
void post()
{
std::unique_lock<std::mutex> lock(mtx_);
++resLimit_;
cond_.notify_one();
}
private:
int resLimit_;
std::mutex mtx_;
std::condition_variable cond_;
};
|
(⭐)Result设计
先分析一下局势:
- Task里面肯定有结果
- 外部有一个Result要接收结果
- Task里面的结果怎么巧妙地转移到Result上面?
- 其实Task不用专门有一个Any成员变量保存。
- 可以直接在Task中保存一个Result指针。
- 外部Result也绑定一个Task作为成员对象。为了让Task延长生命期,Result需要用
shared_ptr<Task>构造。
Result构造函数中,只需要执行:task_->setResult(this);,便可以移花接木,把Task成员变量result_指向外部的Result。- 这样,Task内部,run完之后,返回了Any,Task便可以主动调用
result_->setVal(run())。把结果写回外部的Result内部。
submitTask接口返回类型需要让用户能接收到线程任务的返回值,并且要求可以是任意类型,所以改为Result。相应的,我们需要设计这样的Result类型。
- 思考,return时用下面哪种方式?
task->getResult();还是Result(task);?- 要执行的task从队列中
taskQue_.pop(),接着调用完毕后Task就会析构(注意,submitTask传入的是shared_ptr,引用计数减1,如果此时没有其他人引用该Task,将会析构,里面的any存储的结果就失效了),即task生命期现在只存在于threadFunc函数中。
- 如果是
task->getResult();
- 若task中的Result是以值形式存的,则肯定不行,因为task析构之后,Result也会析构。
- 若task中的Result是以指针形式存的,则必须指定到一个外部资源保存。比如存到堆上。
- 如果是在堆上保存,还必须提供一个getResult接口,返回Result的指针,即
result_成员变量。这样,可以做到把Result安全地保存下来。
- 但是,可以以更为巧妙的方式!
Result(task);
- Result绑定了这个task(用shared智能指针管理,让task对象的生命期延至和Result对等),在Result的构造函数中,调用
task->setResult(this);!!!居然巧妙地把“外部资源地址”指向了外部待接收结果的Result自己!避免了堆上建立的烦恼。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| class ThreadPool
{
public:
Result submitTask(std::shared_ptr<Task> sp);
};
--------------------------
Result ThreadPool::submitTask(std::shared_ptr<Task> sp)
{
if(...)
{
...
return Result(task);
}
return Result(task);
}
|
经过上面的讨论,Result类成员里需要绑定一个Task对象。即下面的task_。下面是Result成员和其构造。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
class Result
{
public:
Result(std::shared_ptr<Task> task, bool isValid = true);
~Result() = default;
private:
Any any_;
Semaphore sem_;
std::shared_ptr<Task> task_;
std::atomic_bool isValid_;
}
------------------
Result::Result(std::shared_ptr<Task> task, bool isValid)
: isValid_(isValid), task_(task)
{
}
|
成员函数
- 问题1:setVal函数,获取任务执行完的返回值,记录在any成员。
- 问题2:get函数,用户调用这个方法获取task的返回值(没执行完需要阻塞)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| class Result
{
public:
void setVal(Any any);
Any get();
private:
Any any_;
Semaphore sem_;
std::shared_ptr<Task> task_;
std::atomic_bool isValid_;
};
-------------
Any Result::get()
{
if(!isValid_)
{
return "";
}
sem_.wait();
return std::move(any_);
}
void Result::setVal(Any any)
{
this->any_ = std::move(any);
sem_.post();
}
|
Task增加方法,把结果写入Result
思想:在threadFun函数中,不仅要靠task对象Task类中的run方法执行具体哪种任务,还要把任务的返回值给到result,可以用exec来封装,exec没有多态,run有多态。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| void Task::exec()
{
if(result_ != nullptr)
{
result_->setVal(run());
}
}
----------------
class Task
{
public:
Task();
~Task() = default;
void exec();
void setResult(Result *res);
virtual Any run() = 0;
private:
Result *result_;
};
----------------
void Task::setResult(Result *res)
{
result_ = res;
}
Task::Task()
: result_(nullptr)
{
}
----------------
Result::Result(std::std::shared_ptr<Task> task, bool isValid)
: isValid_(isValid), task_(task)
{
task_->setResult(this);
}
|
测试2(Master - Slave模型)
Master - Slave模型,Master线程用来分解任务,然后给各个Slave线程分配任务,等待各个Slave线程执行完任务,返回结果。最后Master线程合并各个任务结果,输出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| class MyTask : public Task
{
public:
MyTask(int begin, int end)
: begin_(begin), end_(end)
{
}
Any run()
{
std::cout << "tid:" << std::this_thread::get_id()
<< "begin!" << std::endl;
uLong sum = 0;
for(uLong i = begin_; i <= end_; ++i)
sum += i;
std::cout << "tid:" << std::this_thread::get_id()
<< "end!" << std::endl;
return sum;
}
};
using uLong = unsigned long long;
int main()
{
ThreadPool pool;
pool.start(4);
Result res1 = pool.submitTask(std::make_shared<MyTask>(1, 100000000));
Result res2 = pool.submitTask(std::make_shared<MyTask>(100000001, 200000000));
Result res3 = pool.submitTask(std::make_shared<MyTask>(200000001, 300000000));
uLong sum1 = res1.get().cast_<uLong>();
uLong sum2 = res2.get().cast_<uLong>();
uLong sum3 = res3.get().cast_<uLong>();
cout << sum1 + sum2 + sum3 << endl;
}
|
测试结果:
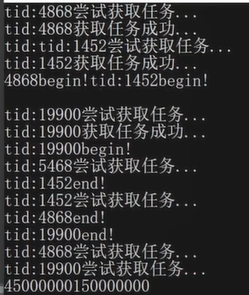
cached模式线程池
主要的使用点:submitTask函数中,可能需要根据任务数量和空闲线程的数量,判断是否需要创建新的线程。
- 需要处理的问题
- 问题1,用户自己如何设置线程池的工作模式
- 问题2,submitTask函数中,根据任务数量和空闲线程的数量,判断是否需要创建新的线程
- 问题3,threadFunc函数中,有可能已经创建了很多的线程,如果空闲时间超过60s,需要结束、回收。
1
2
3
4
5
6
7
8
| int main()
{
ThreadPool pool;
pool.setMode(PoolMode::MODE_CACHED);
pool.start(4);
}
|
切换工作模式
为了防止用户在线程池启动后再去切换线程池的工作模式,我们需要给线程池添加一个状态变量,以控制用户能否对线程池的工作模式进行切换。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| class ThreadPool
{
public:
private:
bool checkRunningState() const;
private:
std::atomic_bool isPoolRunning_;
};
-------------------------------------------
ThreadPool::ThreadPool()
: initThreadSize_(0),
taskSize_(0),
taskQueMaxThreshHold_(TASK_MAX_THRESHHOLD),
poolMode_(PoolMode::MODE_FIXED),
isPoolRunning_(false)
{
}
void ThreadPool::start(int initThreadSize)
{
isPoolRunning_ = true;
}
bool ThreadPool::checkRunningState() const
{
return isPoolRunning_;
}
------------------------------------------
void ThreadPool::setMode(PoolMode mode)
{
if(checkRunningState())
return;
poolMode_ = mode;
}
|
创建更多线程
cached模式:任务处理比较紧急,场景是小而快的任务。
ThreadPool需要添加记录一个空闲线程数量的变量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| class ThreadPool
{
public:
private:
private:
std::atomic_int idleThreadSize_;
}
-------------------------------------------
ThreadPool::ThreadPool()
: initThreadSize_(0),
taskSize_(0),
idleThreadSize_(0),
taskQueMaxThreshHold_(TASK_MAX_THRESHHOLD),
poolMode_(PoolMode::MODE_FIXED),
isPoolRunning_(false)
{
}
void ThreadPool::start(int initThreadSize)
{
for(int i = 0; i < initThreadSize_; ++i)
{
threads_[i]->start();
++idleThreadSize_;
}
}
void ThreadPool::threadFunc()
{
for(;;)
{
std::shared_ptr<Task> task;
{
notEmpty_.wait(lock, [&]()->bool {return taskQue_.size()>0;});
--idleThreadSize_;
}
notFull_.notify_all();
}
if(task != nullptr) task -> exec();
++idleThreadSize_;
}
|
现在来增加 submitTask 函数对 cached 模式处理的细节。
有一点要注意,就是尽管任务非常多,但是我们要对线程的数量设一定的上限值。
即需要给 ThreadPool 类增加一个线程数量阈值变量。
然后为了比较线程池当前线程的数量状况,也要添加一个记录线程总数量的变量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
| const int THREAD_MAX_THRESHHOLD = 10;
class ThreadPool
{
public:
void setThreadSizeThreshHold(int threshhold);
private:
private:
int threadSizeThreshHold_;
std::atomic_int curThreadSize_;
};
ThreadPool::ThreadPool()
: initThreadSize_(0),
taskSize_(0),
idleThreadSize_(0),
curThreadSize_(0),
taskQueMaxThreshHold_(TASK_MAX_THRESHHOLD),
threadSizeThreshHold_(THREAD_MAX_THRESHHOLD),
poolMode_(PoolMode::MODE_FIXED),
isPoolRunning_(false)
{
}
void ThreadPool::start(int initThreadSize)
{
initThreadSize_ = initThreadSize;
curThreadSize_ = initThreadSize;
}
void ThreadPool::setThreadSizeThreshHold(int threshhold)
{
if(checkRunningState() || poolMode_==PoolMode::MODE_FIXED)
return;
threadSizeThreshHold_ = threshhold;
}
-------------------------------------------------------
Result ThreadPool::submitTask(std::shared_ptr<Task> sp)
{
if(poolMode_ == PoolMode::MODE_CACHED
&& taskSize_ > idleThreadSize_
&& curThreadSize_ < threadSizeThreshHold_)
{
auto ptr = std::make_unique<Thread>(std::bind(&ThreadPool::threadFunc, this));
threads_.emplace_back(std::move(ptr));
threads_[threadId]->start();
++curThreadSize_;
++idleThreadSize_;
}
return Result(sp);
}
|
任务处理完毕,回收多余线程
超过initThreadSize_数量的线程要进行回收。
当前时间 比 上一次线程执行完毕的时间 大于 60s 后回收。
C++11中提供了高精度时间API - std::chrono::high_resolution_clock().now();
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
| const int THREAD_IDLE_TIME = 60;
void ThreadPool::threadFunc(int threadid)
{
auto lastTime = std::chrono::high_resolution_clock().now();
for(;;)
{
Task task;
{
std::unique_lock<std::mutex> lock(taskQueMtx_);
std::cout << "tid: " << std::this_thread::get_id()
<< "尝试获取任务..." << std::endl;
while (taskQueue_.size() == 0)
{
if (!isPoolRunning_)
{
threads_.erase(threadid);
std::cout << "threadid: " << std::this_thread::get_id() << " exit!"
<< std::endl;
exitCond_.notify_all();
return;
}
if (poolMode_ == PoolMode::MODE_CACHED)
{
if(std::cv_status::timeout ==
notEmpty_.wait_for(lock, std::chrono::seconds(1)))
{
auto now = std::chrono::high_resolution_clock().now();
auto dur = std::chrono::duration_cast<std::chrono::seconds>(now - lastTime);
if(dur.count() >= THREAD_MAX_IDLE_TIME
&& curThreadSize_ > initThreadSize_)
{
thread_.erase(threadid);
--curThreadSize_;
--idleThreadSize_;
std::cout << "threadid: " << std::this_thread::get_id() << " exit!"
<< std::endl;
return;
}
}
}
else
{
notEmpty_.wait(lock );
}
}
--idleThreadSize_;
std::cout << "tid: " << std::this_thread::get_id()
<< "获取任务成功..." << std::endl;
task = taskQue_.front();
taskQue_.pop();
--taskSize_;
if (taskQue_.size() > 0)
{
notEmpty_.notify_all();
}
notFull_.notify_all();
}
if(task != nullptr)
{
task();
}
++idleThreadSize_;
lastTime = std::chrono::high_resolution_clock().now();
}
}
|
问题:怎么知道线程函数对应的是线程列表容器中的哪一个线程对象?
我们需要有一个映射关系来记录:threadid - thread对象
1
| std::unordered_map<int, std::unique_ptr<Thread>> threads_;
|
所以,Thread对象需要封装一个id值。
然后,在线程函数threadFunc传入int threadid参数。
这样,该 id 的Thread在线程函数中计时自己的空闲时间,若连续 wait 了 60s(每wait一次1s超时返回),说明任务过少,空闲线程过多。
只有知道了 id 号,才能让 ThreadPool 记录的 线程map 精确地删除。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| class Thread
{
public:
using ThreadFunc = std::function<void()>;
Thread(ThreadFunc func);
~Thread();
void start();
int getId() const;
private:
ThreadFunc func_;
static int generateId;
int threadId_;
}
----------------------------------------------
int Thread::generateId_ = 0;
Thread::Thread(ThreadFunc func)
: func_(func), threadId(++generateId_)
{
}
int Thread::getId() const
{
return threadId_;
}
|
然后,最大的变化来了,把原先的线程列表的vector容器变成了unordered_map。
1
2
3
4
5
6
7
| class ThreadPool
{
private:
std::unordered_map<int, std::unique_ptr<Thread>> threads_;
};
|
因此,在 start 启动线程池的操作中,生成线程的动作就要有所变化
要预留一个占位符_1,这是给线程函数的传入参数的位置,threadid。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
void ThreadPool::start(int initThreadSize = std::thread::hardware_concurrency())
{
isPoolRunning_ = true;
initThreadSize_ = initThreadSize;
curThreadSize_ = initThreadSize;
for (int i = 0; i < initThreadSize_; i++)
{
auto ptr = std::make_unique<Thread>(std::bind(&ThreadPool::threadFunc, this, std::placeholders::_1));
int threadId = ptr->getId();
threads_.emplace(threadId, std::move(ptr));
}
for (int i = 0; i < initThreadSize_; i++)
{
threads_[i]->start();
idleThreadSize_++;
}
}
|
改为无序哈希表存储id、Thread对象映射关系,后的代码调整
submitTask
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| Result ThreadPool::submitTask(std::shared_ptr<Task> sp)
{
if(poolMode == PoolMode::MODE_CACHED
&& taskSize_ > idleThreadSize_
&& curThreadSize_ < threadSizeThreshHold_)
{
auto ptr = std::make_unique<Thead>(std::bind(&ThreadPool::threadFunc, this));
int threadId = ptr->getId();
threads_.emplace(threadId, std::move(ptr));
threads_[threadId]->start();
++curThreadSize_;
++idleThreadSize_;
}
return Result(sp);
}
|
ThreadPool的threadFunc(int threadid)接口添加int参数
1
2
3
4
5
6
7
8
9
10
11
| class ThreadPool
{
public:
...
private:
void threadFunc(int threadid);
...
private:
...
}
|
Thread中using ThreadFunc的std::function<void(int)>
1
2
3
4
5
6
| class Thread
{
public:
using ThreadFunc = std::function<void(int)>;
}
|
Thread的start,多传入一个threadId_
1
2
3
4
5
| void Thread::Start()
{
std::thread t(func_, threadId_);
t.detach();
}
|
测试3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
| class MyTask : public Task
{
public:
MyTask(int begin, int end)
: begin_(begin), end_(end)
{
}
Any run()
{
std::cout << "tid:" << std::this_thread::get_id()
<< "begin!" << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(3));
uLong sum = 0;
for(uLong i = begin_; i <= end_; ++i)
sum += i;
std::cout << "tid:" << std::this_thread::get_id()
<< "end!" << std::endl;
return sum;
}
};
---------------------------------------------------------------------------------------
Result ThreadPool::submitTask(std::shared_ptr<Task> sp)
{
if(poolMode == PoolMode::MODE_CACHED
&& taskSize_ > idleThreadSize_
&& curThreadSize_ < threadSizeThreshHold_)
{
std::cout << ">>> create new thread ..." << std::endl;
auto ptr = std::make_unique<Thead>(
std::bind(&ThreadPool::threadFunc,
this, std::placeholders::_1)
);
int threadId = ptr->getId();
threads_.emplace(threadId, std::move(ptr));
threads_[threadId]->start();
++curThreadSize_;
++idleThreadSize_;
}
return Result(sp);
}
--------------------------------------------------------------------------------------
const int THREAD_MAX_IDLE_TIME = 10;
void ThreadPool::threadFunc()
{
if(dur.count() >= THREAD_MAX_IDLE_TIME
&& curThreadSize_ > initThreadSize_)
{
...
}
}
--------------------------------------------------------------------------------------
const int TASK_MAX_THRESHHOLD = INT32_MAX;
const int THREAD_MAX_THRESHHOLD = 10;
int main()
{
{
ThreadPool pool;
pool.setMode(PoolMode::MODE_CACHED);
pool.start(4);
Result res1 = pool.submitTask(std::make_shared<MyTask>(1,100000000));
Result res2 = pool.submitTask(std::make_shared<MyTask>(100000001,200000000));
Result res3 = pool.submitTask(std::make_shared<MyTask>(200000001,300000000));
pool.submitTask(std::make_shared<MyTask>(200000001,300000000));
pool.submitTask(std::make_shared<MyTask>(200000001,300000000));
pool.submitTask(std::make_shared<MyTask>(200000001,300000000));
uLong sum1 = res1.get().cast_<uLong>();
uLong sum2 = res2.get().cast_<uLong>();
uLong sum3 = res3.get().cast_<uLong>();
}
getchar();
}
|
测试结果
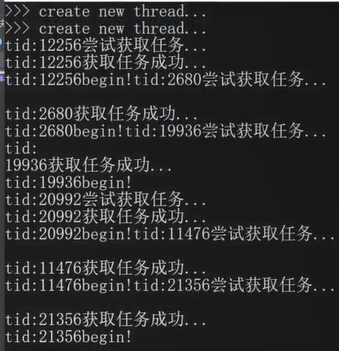
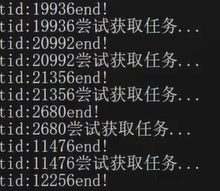

问题:ThreadPool对象析构以后,怎么样把线程池相关的线程资源全部回收
在析构函数中,用户线程需要等待线程池线程,这是两类不同的线程,需要通过线程间通信来达到等待完成。
线程间通信可以用信号量、条件变量,都可以,我们在ThreadPool类中使用一个条件变量exitCond_。
1
2
3
4
5
6
7
8
9
10
11
12
| class ThreadPool
{
public:
...
private:
...
private:
...
std::condition_variable exitCond_;
...
}
|
在析构函数中,
- 置
isPoolRunning_为false,如此线程函数进去之后发现线程池要关闭了,
- 如果任务队列为0,则就直接退出。
- 如果任务队列不为0则取任务。
notEmpty_.notify_all();,最后一波唤醒,让所有线程醒来,看有没有任务,没任务就收工。- ThreadPool关注
exitCond_,若有人通知了,则说明是线程陆陆续续在退出了,直到threads_.size() == 0,说明所有线程都退出了。这时候,线程池就可以放心析构了。
1
2
3
4
5
6
7
8
| ThreadPool::~ThreadPool()
{
isPoolRunning_ = false;
notEmpty_.notify_all();
std::unique_lock<std::mutex> lock(taskQueMtx_);
exitCond_.wait(lock, [&]()->bool {return threads_.size() == 0;});
}
|
项目推进时遇到了什么问题?
- 实现核心功能时的问题:如何通用地获取提交任务后的返回值,即Any,Result的设计。
- 设计线程池资源回收的,是以…的方式实现的,测试时,有时会出现死锁的现象
调试方法
gdb调试,attach到正在死锁的进程,把线程栈打印出来,在哪一个函数的哪一句话不动了。
问题要素:
1、线程池要结束,要释放整个池子的资源了。
2、线程池的成员isPoolRunning_状态置为了false。
以上两个要素
1,不受线程池内的线程目前的状态而影响,线程的状态:在等待任务、在执行任务。
2,isPoolRunning_必将影响线程的代码路径。
isPoolRunning_在线程池start时置为true。
我们设计的ThreadPool不用考虑成员的析构问题,最主要的两个成员容器:
1、无序map中的线程对象是unique_ptr管理的。
2、queue中的任务队列是shared_ptr管理的。
3、其余的变量都是非指针变量。
ThreadPool析构时仅仅只是把isPoolRunning_置false就可以了吗?
当然不可以。线程池要等待线程池里面所有的线程返回。
目前线程可能在threadFunc函数中阻塞在notEmpty上,另一种是正在执行任务中。
此时就需要不同线程的通信。即用户线程和线程池中的线程之间进行通信。
用信号量、条件变量都可以。
我们用条件变量。
在ThreadPool中定义一个成员,std::condition_variable exitCond_; 等待线程资源全部回收
1
2
3
4
5
6
7
8
9
10
| ThreadPool::~ThreadPool()
{
isPoolRunning_ = false;
notEmpty_.notify_all();
std::unique_lock<std::mutex> lock(taskQueMtx_);
exitCond_.wait(lock, [&]()->bool {return threads_.size()==0;});
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
int main()
{
ThreadPool pool;
pool.start(4);
Result res1 = pool.submitTask(std::make_shared<MyTask>(1,10000000));
uLong sum1 = res1.get().cast_<uLong>();
cout << sum1 << endl;
cout << "main over!" << endl;
}
|
代码分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
ThreadPool::~ThreadPool()
{
isPoolRunning_ = false;
notEmpty_.notify_all();
std::unique_lock<std::mutex> lock(taskQueMtx_);
exitCond_.wait(lock, [&]()->bool {return threads_.size()==0;});
}
void ThreadPool::threadFunc(int threadid)
{
auto lastTime = ...;
while(isPoolRunning_)
{
std::shared_ptr<Task> task;
{
std::unique_lock<std::mutex> lock(taskQueMtx_);
std::cout << "tid: " << std::this_thread::get_id()
<< "尝试获取任务... " << std::endl;
while(taskQue_.size() == 0)
{
if(poolMode_ == PoolMode::MODE_CACHED)
{
if(std::cv_status::timeout ==
notEmpty_.wait_for(lock, std::chrono::seconds(1)))
{
return;
}
}
else
{
notEmpty_.wait(lock);
}
}
if(!isPoolRunning_)
{
threads_.erase(threadid);
std::cout << "threadid:" << std::this_thread::get_id()
<< " exit:" << std::endl;
exitCond_.notify_all();
return;
}
}
--idleThreadSize_;
std::cout << "tid:" << std::this_thread::get_id()
<< "获取任务成功..." << std::endl;
}
}
|
第一种情况:线程是固定模式,任务队列空时,等待在notEmpty_上。这种情况我们不怕,因为线程池析构函数已经写了notEmpty_.notify_all();
第二种情况:task->exec()中,即线程执行任务中。这种也没事,线程执行完任务再次进入while循环判断时发现isPoolRunning_为false了,则删除线程,退出。
第三种情况才是关键,线程task->exec() 执行完后进入了while (isPoolRunning_)循环,到了获取锁语句之前的位置。这时,线程池关闭了,也就是说在Running状态切换为false!现在,线程池、子线程的下一个动作都是对taskQueMtx_进行加锁!而最关键的,如果能够“阴差阳错地”进入第二个while循环,那么就会在notEmpty_上等死,因为此时线程池在语义上是已经关闭了,没人再去唤醒它。
第三种情况中的第一种情况:线程池抢到锁,又在exitCond_上wait阻塞,而子线程虽然能抢到锁,但是会死在notEmpty_上。
第三种情况中的第二种情况:子线程抢到锁,往下执行,则没有任务时,在notEmpty_上等待会放弃锁,阻塞自己,线程池之后会抢到锁,等待线程结束。这时没有人去唤醒notEmpty_上的子线程了。死锁。这是问题之关键。
那么,第三种情况怎么解决死锁问题呢?
我们注意到,第三种情况中第一种情况的问题是因为线程池exitCond_.wait()后,进入了第一个while后争抢lock的线程可能拿到锁后,顺理成章进入第二个while中,若恰逢没有任务,则死在了notEmpty_上。所以为了防止错误的时机进入到第二个while循环中,在条件处首先再判断一次isPoolRunning_。
3.1的解决方案:锁+双重判断
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| void ThreadPool::threadFunc(int threadid)
{
auto lastTime = ...;
while(isPoolRunning_)
{
std::shared_ptr<Task> task;
{
std::unique_lock<std::mutex> lock(taskQueMtx_);
std::cout << ... << std::endl;
while(isPoolRunning_ && taskQue_.size()==0)
{
if(poolMode_ == PoolMode::MODE_CACHED)
{
if(std::cv_status::timeout ==
notEmpty_.wait_for(lock, std::chrono::seconds(1)))
{
return;
}
}
else
{
notEmpty_.wait(lock);
}
}
if(!isPoolRunning_)
{
break;
}
--idleThreadSize_;
std::cout << "获取任务成功" << std::endl;
task = taskQue_.front();taskQue_.pop();
--taskSize_;
notFull_.notify_all();
}
if(task != nullptr)task->exec();
++idleThreadSize_;
lastTime = ...;
}
threads_.erase(threadid);
std::cout << "线程退出" << std::endl;
exitCond_.notify_all();
return;
}
|
如此一来,线程池先抢到锁,再在exitCond_上wait阻塞释放锁后,子线程得到锁向下走到了第二个while语句,由于再次判断isPoolRunning_,这时发现改变为false了,就不会走到notEmpty_.wait()了。灰溜溜去做删除动作了。
3.2的解决方案:调整加锁位置
虽然3.1解决了isPoolRunning状态脏读这个漏洞问题,但是依旧不能解决“子线程先抢到锁”从而在notEmpty_上等待这种情况发生。即使子线程释放了锁,但是没有人再去唤醒notEmpty_,因为原来的语序是先唤醒,再抢锁。所以我们要让用户线程的加锁、唤醒放在子线程wait之后,要让子线程wait释放了锁之后,才让用户线程唤醒notEmpty_!于是:
1
2
3
4
5
6
7
| ThreadPool::~ThreadPool()
{
isPoolRunning_ = false;
std::unique_lock<std::mutex> lock(taskQueMtx_);
notEmpty_.notify_all();
exitCond_.wait(lock, [&]()->bool {return threads_.size()==0;});
}
|
调换了一下第二、第三句,即子线程先抢到锁后wait在notEmpty_上后释放锁,用户线程再抢到锁之后才去notify_all()它,那么阻塞的子线程被唤醒了,往下执行,发现isPoolRunning_变为false了,灰溜溜去做删除动作了。完美解决问题。
编译为动态库
直接在命令行使用g++编译
1
| g++ -o libxcg-threadpool.so -fPIC -shared [源文件如: threadpool.cpp] -std=c++17
|
用cmake构建编译
根目录
1
2
3
4
5
6
7
8
9
10
| cmake_minimum_required(VERSION 3.0.0)
project(xcg-threadpool)
set(CMAKE_CXX_FLAGS ${CMAKE_CXX_FLAGS} -g)
set(LIBRARY_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/lib)
include_directories(${PROJECT_SOURCE_DIR}/include)
add_subdirectory(src)
|
src目录
1
2
3
4
5
6
|
aux_source_directory(. SRC_LIST)
add_library(${PROJECT_NAME} SHARED ${SRC_LIST})
target_link_libraries(xcg-threadpool pthread)
|
使用动态库编译可执行文件
首先需要把动态库libxcg-threadpool.so移动到/usr/lib或/usr/local/lib;把动态库对应的头文件threadpool.h移动到/usr/include或/usr/local/include下。
1
| g++ -o main main.cpp -std=c++17 -lxcg-threadpool -lpthread
|
重构简洁版的线程池
要对外提供一个简单易用的submitTask接口。
让用户直接传一个:future result = submitTask(func, 1, 2);
而不用再去继承一个抽象的Task了,甚至还得make_shared<MyTask()>(func, 1, 2);,这样太繁琐了。
主要用到的技巧就是:可变参模板,万能引用,函数绑定器,完美转发。
submitTask的返回类型无法写出,需要用到auto占位,之后用decltype进行推导。
ThreadPool成员变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| private:
std::unordered_map<int, std::unique_ptr<Thread>> threads_;
int initThreadSize_;
int threadSizeThreshHold_;
std::atomic_int curThreadSize_;
std::atomic_int idleThreadSize_;
using Task = std::function<void()>;
std::queue<Task> taskQue_;
std::atomic_int taskSize_;
int taskQueMaxThreshHold_;
std::mutex taskQueMtx_;
std::condition_variable notFull_;
std::condition_variable notEmpty_;
std::condition_variable exitCond_;
PoolMode poolMode_;
std::atomic_bool isPoolRunning_;
};
|
优化submitTask
以下的关键点:任务队列中存储的任务(lambda)捕获了shared_ptr,因此当这个任务被执行时,它仍然持有一个shared_ptr,这样packaged_task就不会在执行前被销毁。
当任务执行完毕,这个lambda就会被销毁,那么它持有的shared_ptr也会被销毁(引用计数减一)。如果这时没有其他shared_ptr引用(比如在submitTask函数中,除了任务队列中的那个shared_ptr,还有submitTask函数中的局部变量task),那么packaged_task就会在任务执行完毕后被销毁。
但是,在submitTask函数中,我们返回了一个future,这个future是与packaged_task关联的。值得注意的是,std::packaged_task的析构不会影响其关联的future吗?不会。因为std::future是通过共享状态(shared state)与std::packaged_task关联的,这个共享状态独立于packaged_task对象。也就是说,即使packaged_task对象销毁了,只要共享状态还存在(因为future还持有),那么future仍然可以正常工作。所以,packaged_task对象销毁后,future的get()仍然可以正常返回结果(或者异常)。
我们要明确的:
future只是负责持有结果。但
future 不会延长 task 的生命周期,
std::future 只管理共享状态(shared state)的生命周期(存储结果的内存区域)- 不会延长关联的
packaged_task 对象的生命周期
future 只依赖共享状态,不依赖 packaged_task 对象本身。即共享状态的生命周期独立于 packaged_task
- 由最后一个引用它的
future 或 shared_future 管理
- 与
packaged_task 对象的销毁无关
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| classDiagram
class PackagedTask {
+operator()()
+get_future()
-shared_state*
}
class SharedState {
+result
+ready_flag
}
class Future {
+shared_state*
}
PackagedTask --> SharedState : 独占拥有
Future --> SharedState : 只读引用
|
关键点:
packaged_task 独占拥有共享状态的生命周期future 只持有对共享状态的弱引用- 移动、销毁
packaged_task 会转移共享状态的所有权。但是不会销毁SharedState,因为外部还有Future在观察。
- 因此,其实也可以在之前就保存下来task的future,然后再去把task转移给任务队列。这样无所谓task是否在外部获得结果之前销毁了。
- 但是这样会限制task在移动之后的操作,无法在移动之后获得future了。
关键点:
- 共享所有权:
- 任务队列和工作线程共同持有
shared_ptr。
- (⭐)当 lambda 被放入队列时,
shared_ptr 的引用计数增加
- 最后一个持有者释放时
packaged_task 才会销毁
- 当队列中的 lambda 被销毁时,
shared_ptr 引用计数减少
- 生命周期安全:
- 即使
submitTask 返回,只要队列或线程持有 shared_ptr
packaged_task 对象会一直存活到任务执行完成
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| template<typename Func, typename... Args>
auto submitTask(Func&& func, Args&&... args) -> std::future<decltype(func(args...))>
{
using RType = decltype(func(args...));
auto task = std::make_shared<std::packaged_task<RType()>>(
std::bind(std::forward<Func>(func), std::forward<Args>(args)...));
std::future<RType> result = task->get_future();
std::unique_lock<std::mutex> lock(taskQueMtx_);
if (!notFull_.wait_for(lock, std::chrono::seconds(1),
[&]() -> bool { return taskQue_.size() < taskQueMaxThreshHold_; }))
{
std::cerr << "task queue is full, submit task failed." << std::endl;
std::promise<RType> p;
p.set_exception(std::make_exception_ptr(std::runtime_error("Task queue full")));
return p.get_future();
}
taskQue_.emplace([task]() { (*task)(); });
++taskSize_;
notEmpty_.notify_all();
if (poolMode_ == PoolMode::MODE_CACHED
&& taskSize_ > idleThreadSize_
&& curThreadSize_ < threadSizeThreshHold_)
{
std::cout << ">>> create new thread..." << std::endl;
auto ptr = std::make_unique<Thread(std::bind(&ThreadPool::threadFunc, this, std::placeholder::_1));
int threadId = ptr->getId();
threads_.emplace(threadId, std::move(ptr));
threads_[threadId]->start();
++curThreadSize_;
++idleThreadSize_;
}
return result;
}
|
再次优化submitTask
future 只依赖共享状态,不依赖 packaged_task 对象本身。即共享状态的生命周期独立于 packaged_task
- 由最后一个引用它的
future 或 shared_future 管理
- 与
packaged_task 对象的销毁无关
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| classDiagram
class PackagedTask {
+operator()()
+get_future()
-shared_state*
}
class SharedState {
+result
+ready_flag
}
class Future {
+shared_state*
}
PackagedTask --> SharedState : 独占拥有
Future --> SharedState : 只读引用
|
关键点:
packaged_task 独占拥有共享状态的生命周期future 只持有对共享状态的弱引用- 移动、销毁
packaged_task 会转移共享状态的所有权。但是不会销毁SharedState,因为外部还有Future在观察。
- 因此,其实也可以在之前就保存下来task的future,然后再去把task转移给任务队列。这样无所谓task是否在外部获得结果之前销毁了。
- 移动task的缺点:但是这样会限制task在移动之后的操作,无法在移动之后获得future了。
优化点:
- 完美转发捕获(C++20)代替
std::bind,更高效且避免额外开销
- 移动task到lambda中,而不是建立
shared_ptr来管理它。比shared_ptr版本更轻量高效(减少一次堆分配)。
注意点:
为什么需要mutable?
因为packaged_task的operator()调用会改变packaged_task对象(它内部会执行任务并将结果存储到共享状态,所以会改变packaged_task的状态),因此lambda的调用运算符必须声明为mutable,否则编译器会认为你在一个const的lambda中试图修改捕获的对象。
所以,这里mutable是必须的。
在完美转发捕获可变参时,为什么也需要加mutable?
我们通过完美转发捕获了func和args。在lambda体内,我们调用了func,并使用了std::forward<Args>(args)...来转发参数。由于转发可能意味着移动(当参数是右值时),这会修改捕获的args(移动后,对象的状态被改变,通常为空或有效状态被转移)。因此,我们需要mutable来允许对捕获的变量进行修改(包括移动操作)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| template<typename Func, typename... Args>
auto submitTask(Func&& func, Args&&... args) -> std::future<decltype(func(args...))>
{
using RType = decltype(func(args...));
auto task = std::packaged_task<RType()>(
[func = std::forward<Func>(func), ...args = std::forward<Args>(args)] () mutable
{
return func(std::forward<Args>(args)...);
});
std::future<RType> result = task.get_future();
std::unique_lock<std::mutex> lock(taskQueMtx_);
if (!notFull_.wait_for(lock, 1s,
[&] { return taskQue_.size() < taskQueMaxThreshHold_; }))
{
std::promise<RType> p;
p.set_exception(
std::make_exception_ptr(std::runtime_error("Task queue full")));
return p.get_future();
}
taskQue_.emplace([task = std::move(task)]() mutable {
task();
});
++taskSize_;
notEmpty_.notify_all();
if (poolMode_ == PoolMode::MODE_CACHED &&
taskSize_ > idleThreadSize_ &&
curThreadSize_ < threadSizeThreshHold_)
{
}
return result;
}
|
threadFunc的重构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
| const int THREAD_IDLE_TIME = 60;
void ThreadPool::threadFunc(int threadid)
{
auto lastTime = std::chrono::high_resolution_clock().now();
for(;;)
{
Task task;
{
std::unique_lock<std::mutex> lock(taskQueMtx_);
std::cout << "tid: " << std::this_thread::get_id()
<< "尝试获取任务..." << std::endl;
while (taskQueue_.size() == 0)
{
if (!isPoolRunning_)
{
threads_.erase(threadid);
std::cout << "threadid: " << std::this_thread::get_id() << " exit!"
<< std::endl;
exitCond_.notify_all();
return;
}
if (poolMode_ == PoolMode::MODE_CACHED)
{
if(std::cv_status::timeout ==
notEmpty_.wait_for(lock, std::chrono::seconds(1)))
{
auto now = std::chrono::high_resolution_clock().now();
auto dur = std::chrono::duration_cast<std::chrono::seconds>(now - lastTime);
if(dur.count() >= THREAD_MAX_IDLE_TIME
&& curThreadSize_ > initThreadSize_)
{
thread_.erase(threadid);
--curThreadSize_;
--idleThreadSize_;
std::cout << "threadid: " << std::this_thread::get_id() << " exit!"
<< std::endl;
return;
}
}
}
else
{
notEmpty_.wait(lock );
}
}
--idleThreadSize_;
std::cout << "tid: " << std::this_thread::get_id()
<< "获取任务成功..." << std::endl;
task = taskQue_.front();
taskQue_.pop();
--taskSize_;
if (taskQue_.size() > 0)
{
notEmpty_.notify_all();
}
notFull_.notify_all();
}
if(task != nullptr)
{
task();
}
++idleThreadSize_;
lastTime = std::chrono::high_resolution_clock().now();
}
}
|
测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| int sum(int a, int b)
{
return a + b;
}
int main()
{
ThreadPool pool;
pool.setMode(PoolMode::MODE_CACHED);
pool.start(2);
future<int> res1 = pool.submitTask(sum, 1, 2);
future<int> res2 = pool.submitTask([](int begin, int end) -> int
{
int sum = 0;
for (int i = begin; i <= end; ++i)
{
sum += i;
}
return sum;
}, 1, 100);
future<int> res3 = pool.submitTask(sum, 1, 2);
future<int> res4 = pool.submitTask(sum, 1, 2);
cout << res1.get() << endl;
cout << res2.get() << endl;
cout << res3.get() << endl;
cout << res4.get() << endl;
}
|