本章内容:
什么是指针
指针的定义
指针的应用
指针的运算
指针与数组的关系
指针和数组,函数示例
二级指针
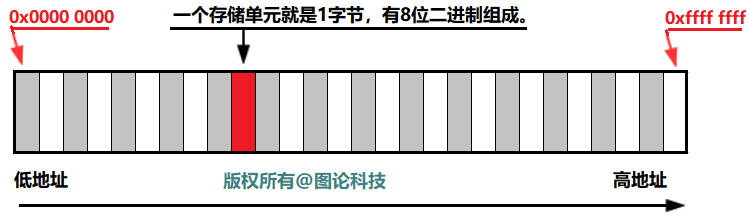
计算机中所有的数据都必须放在内存中,不同类型的数据占用的字节数不一样,例如int占用 4 个字节,char 占用 1 个字节。为了正确地访问这些数据,必须为每个字节都编上号码,就像门牌号一样,每个字节的编号是唯一的,根据编号可以准确地找到某个字节。 我们将内存中字节的编号称为地址(Address)或指针(Pointer)。地址从 0 开始依次增加,对于 32 位环境,程序能够使用的内存为 4GB。0x0000 0000,最大的地址为0XFFFF FFFF。
*的总结
表示乘法。
表示定义一个指针变量,以和普通变量区分开
表示解引用。获取指针指向的数据,是一种间接操作。
*号运算符所在的环境不一样,*号的含意也不一样。
1 2 3 4 5 6 7 8 9 10 11 int main () { int a = 10 , b = 20 ; int c = a * b; int * p; p = &a; * p = 100 ; return 0 ; }
要么初始化为空,要么指向已有变量的地址。否则指针指向的位置不可控,可能在操作指针时会改变其他正在运转的值。
1 2 3 4 5 6 7 8 9 10 int main () { int *p , s; char *cpa , *cpb; int a = 10 ; int * ip; ip = &a; return 0 ; }
解析存储单元的大小;
指针变量加1的能力。
如:
double da = *dp;int ib = *ip;char cc = *cp;
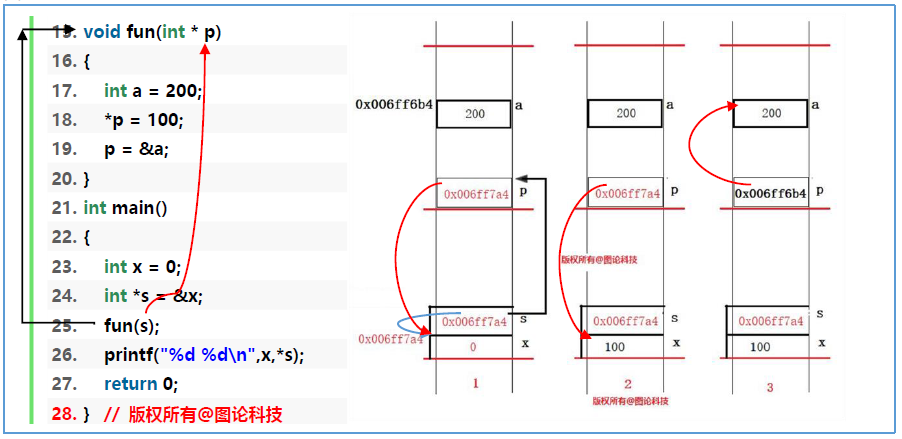
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void fun (int *p) { int a = 200 ; *p = 100 ; p = &a; } int main () { int x = 0 ; int *s = &x; fun(s); printf ("%d %d\n" ,x,*s); return 0 ; }
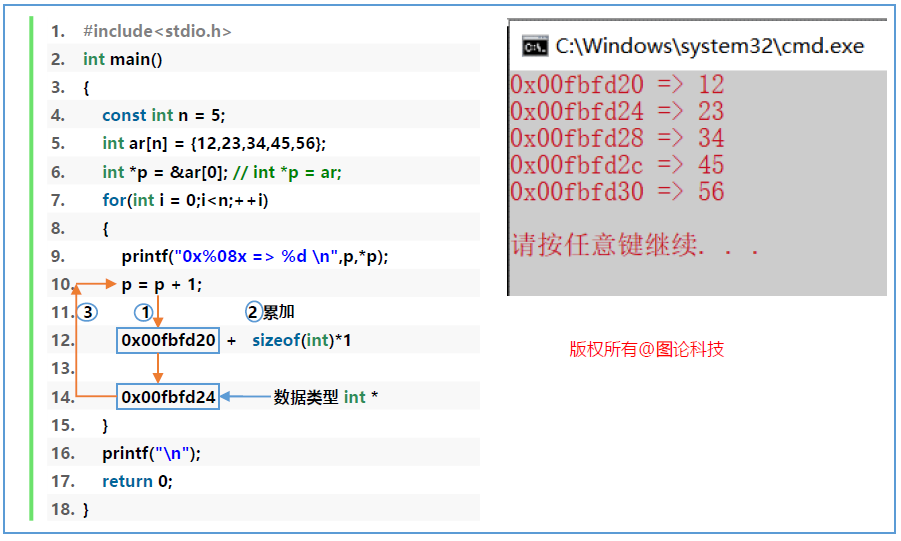
typename * p;p = p + 1;被编译器解释成:p = p + sizeof(typename) * 1;
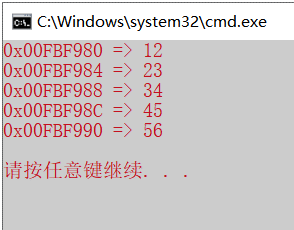
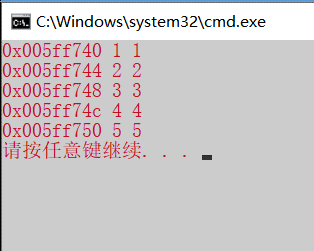
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <stdio.h> int main () { const int n = 5 ; int ar[n]={12 ,23 ,34 ,45 ,56 }; int *ip = &ar[0 ]; for (int i = 0 ;i<n;++i) { printf ("0x%08X => %d \n" ,ip,*ip); ip = ip + 1 ; } printf ("\n" ); return 0 ; }
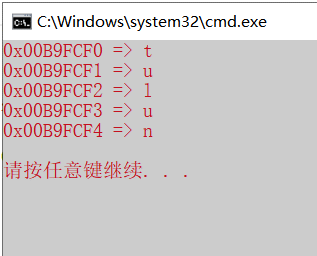
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <stdio.h> int main () { const int n = 5 ; char ar[n]={'t' ,'u' ,'l' ,'u' ,'n' }; char *cp = &ar[0 ]; for (int i = 0 ;i<n;++i) { printf ("0x%08X => %c \n" ,cp,*cp); cp = cp + 1 ; } printf ("\n" ); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <stdio.h> int main () { const int n = 5 ; double ar[n]={1.2 , 2.3 , 3.4 , 4.5 , 5.6 }; double *dp = &ar[0 ]; for (int i = 0 ;i<n;++i) { printf ("0x%08X => %f \n" ,dp,*dp); dp = dp + 1 ; } printf ("\n" ); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int main () { int ar[5 ]={12 , 23 , 34 , 45 , 56 }; int *p = ar; int x = 0 ; int y = 0 ; x = *p++; y = *p; printf ("%d %d \n" ,x,y); x = ++*p; y = *p; printf ("%d %d \n" ,x,y); x = *++p; y = *p; printf ("%d %d \n" ,x,y); return 0 ; }
+1的能力,偏移量。
对内存的解析能力。
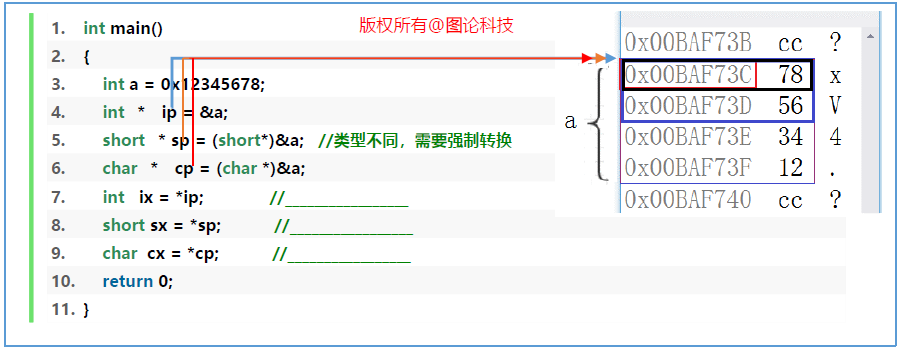
1 ix=0x12345678 sx=0x5678 cx=0x78
地址值
指针指向的数据类型
数组名被看作该数组的第一个元素在内存中的首地址(仅在sizeof操作中例外,该操作给出数组所占内存大小)。
数组名在表达式中被自动转换为一个指向数组第一个元素的指针常量。
数组名是指针,非常方便,但是却丢失了数组另一个要素:数组的大小,即数组元素的数量。编译器按数组定义时的大小分配内存,但运行时(run time)对数组的边界不加检测。这会带来无法预知的严重错误。
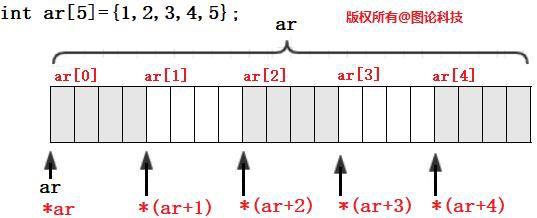
C提供根据数组的存储地址访问数组元素的方法。上图中ar是数组第一个元素的地址,所以*ar是数组的第一个元素ar[0],而ar+1是数组第二个元素的地址,*(ar+1)是第二个元素ar[1]本身。指针加1,则地址移动一个数组元素所占字节数。
C语言的下标运算符[]是以指针作为操作数的,ar[i]被编译系统解释为*(ar+i),即表示为ar所指(固定不可变)元素向后第i个元素。无论以下标方式或指针方式存取数组元素时,系统都是转换为指针方法实现。逻辑上有两种方式,物理上只有一种方式。
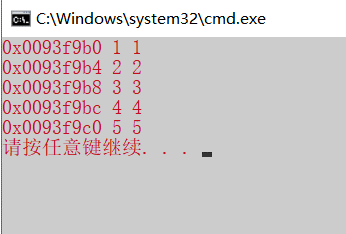
1 2 3 4 5 6 7 8 9 10 int main () { const int n = 5 ; int ar[n] = {1 , 2 , 3 , 4 , 5 }; for (int i = 0 ;i < n;++i) { printf ("0x%08x %d %d \n" ,ar+i, ar[i], *(ar+i)); } return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 int main () { const int n = 5 ; int ar[n] = {1 ,2 ,3 ,4 ,5 }; int *p = ar; for (int i = 0 ;i<n;++i) { printf ("0x%08x %d %d\n" ,p+i,p[i],*(p+i)); } return 0 ; }
用数组作为函数的形参,数组将退化为指针类型。
如果想要在函数中传递一个一维数组作为参数,必须以下面三种方式来声明函数形式参数,这三种声明方式的结果是一样的,因为每种方式都会转成指针。
1 2 3 void Print_Array (int br[],int n) ; void Print_Array (int br[5 ],int n) ; void Print_Array (int *br,int n) ;
要点:为什么数组作为函数的形参会退化为指针呢?我们将从时间效率和空间效率上分析。
我们先假设数组作为函数的形参,我们分析一下调用过程;
1 2 3 4 5 6 7 8 9 10 11 12 void Print_Array (int br[5 ],int n) { int ar_len = sizeof (br); printf ("ar_len : %d \n" ,ar_len); } int main () { const int n = 5 ; int ar[n] = {1 ,2 ,3 ,4 ,5 }; Print_Array(ar,n); return 0 ; }
1 2 3 4 5 6 #include <stdio.h> void Print_Ar (int br[10 ]) { int size=sizeof (br); printf ("size: %d \n" ,size); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void Print_Ar (int (*br)[4 ],int row,int col) { printf ("%d %d\n" , row, n); for (int i = 0 ;i < row;++i) { for (int j = 0 ;j < col;++j) { printf ("%d " , br[i][j]); } printf ("\n" ); } printf ("\n" ); }
如果二维数组的形参定义为:int [4][5],同一维数组的道理一样,将会退化为int(*br)[4]。
数组名表示数组首元素的地址,而不是数组的地址。
1 2 3 4 5 6 7 8 9 10 int main () { const int n =5 ; int ar[n] = {12 ,23 ,34 ,45 ,56 }; int * ip = ar; int (*s)[5 ] = &ar; int * pa[5 ]; return 0 ; }
1 2 3 4 5 6 7 8 9 int main () { int a = 10 ; int * p = &a; int a[5 ]; int (*p)[5 ] = &a; }
访问数组时,编译器会把x[y]转换为:*(x+y),对应机器码的基变址寻址。x是基地址。
不带const修饰的指针是自由的,一是自身的值可以改变,二是指向的值可以改变。
1 2 3 4 int a = 10 , b = 20 ;int *p = &a;*p = 100 ; p = &b;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int a=10 ,b=20 ;const int *p = &a;int const *p = &a;*p = 100 ; p = &b; int * const p = &a;int x = *p;*p = 100 ; p = &b; const int * const p = &a;int const * const p = &a;*p = 100 ; p = &b;
1 2 3 4 5 6 7 int a=10 ;const int b=20 ;int *pa=&a;const int * pa1=&a;int * pb=&b;const int * pb=&b;
1 2 3 4 5 6 7 8 9 10 11 12 int main () { const int a=10 ; int b=0 ; int * p=(int *)&a; *p=100 ; b=a; printf ("a=%d\n" ,a); printf ("b=%d\n" ,b); printf ("*p=%d\n" ,*p); }
1 2 3 4 5 6 7 8 9 10 #include <stdio.h> int my_strlen (char * string ) { int count = 0 ; while (*string ++ != '\0' ) { ++count; } return count; }
1 2 3 4 5 6 7 8 9 10 11 12 #include <stdio.h> #include <assert.h> int my_strlen (const int * string ) { assert(string != NULL ); int i=0 ; while (string [i]!='\0' ) { ++i; } return i; }
指针地址的计算——算头不算尾
1 2 3 4 5 6 7 8 9 10 11 12 #include <stdio.h> #include <assert.h> int my_strlen (const int * str) { assert(str!=nullptr); const char * cp = str; while (*cp!='\0' ) { cp++; } return (cp-str); }
不让用计数变量计算字符串长度–指针地址计算
不让用任何变量计算字符串长度–递归函数
1 2 3 4 5 6 7 8 9 int my_strlen2 (const char * string ) { assert(string != nullptr); if (*string ++) { return my_strlen2(string )+1 ; } else return 0 ; }
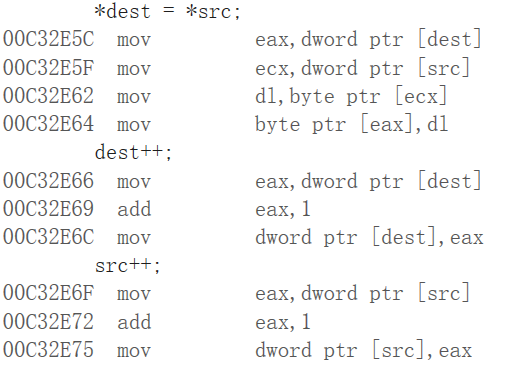
1 2 3 4 5 6 7 8 9 10 11 12 13 14 char * my_strcpy (char * dest,const char * src) { assert(dest != NULL && src != NULL ); char * cp = dest; while (*src != '\0' ) { *dest = *src; dest++; src++; } *dest = '\0' ; return dest; }
对于*dest++ = *src++可以看一下汇编代码,就清楚了
1 2 3 4 5 6 7 8 9 10 #include <stdio.h> #include <assert.h> char * my_strcat (char * dest, const char * src) { assert(dest != nullptr && src != nullptr); char * cp = dest; while (*cp != '\0' ) ++cp; while (*cp++ = *src++); return dest; }
1 2 3 4 5 6 7 8 9 #include <stdio.h> #include <assert.h> char * my_strcat (char * dest, const char * src) { assert(dest != nullptr && src != nullptr); int index = my_strlen(dest); my_strcpy(dest+len, src); return dest; }
1 2 3 4 5 6 7 8 9 10 11 12 int main () { char * stra = "yhp" ; char * strb = "yhp" ; char strc[]="yhp" ; char strd[]="yhp" ; bool x = (stra==strb); bool y = (strc==strd); printf ("x = %d y = %d\n" ,x,y); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <stdio.h> #include <assert.h> int my_strcmp (const char * ap, const char * bp) { assert(ap!=nullptr&&bp!=nullptr); while ((ap||bp)&&(*ap==*bp)) { ap++; bp++; if (*ap=='\0' ||*bp=='\0' )break ; } return *ap-*bp; } int main () { char stra[10 ] = "yhping" ; char strb[10 ] = "yhxing" ; int ans = my_strcmp(stra,strb); printf ("%d\n" , ans); }
1 2 3 4 5 6 7 8 9 10 11 12 13 int main () { short st = 0x0001 ; char * cp = (char *)&st; if (*cp==0x01 ) { printf ("小端\n" ); } else { printf ("大端\n" ); } }
1 2 3 4 5 6 7 8 9 int my_strlen2 (const char * string ) { assert(string != nullptr); if (*string ++) { return my_strlen2(string )+1 ; } else return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 int main () { char * stra = "yhp" ; char * strb = "yhp" ; char strc[]="yhp" ; char strd[]="yhp" ; bool x = (stra==strb); bool y = (strc==strd); printf ("x = %d y = %d\n" ,x,y); }
1 2 3 4 5 6 7 8 9 10 11 12 13 int my_strcmp (const char * ap, const char * bp) { assert(ap != nullptr && bp != nullptr); while (ap&&bp&&*ap == *bp) { ap++; bp++; } return *ap - *bp; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 int FindValue (int * ar,int n,int val) { assert(ar != nullptr); int pos = -1 ; int left = 0 , right = n - 1 ; while (left<=right) { int mid = (left + right) >>2 ; if (val < ar[mid]) { right = mid-1 ; } else if (val > ar[mid]) { left = mid+1 ; } else { while (mid > left && ar[mid - 1 ] == ar[mid]) { --mid; } pos = mid; break ; } } return pos; }
如果数据量非常大,left+right可能会溢出,怎么解决——left + (right - left) / 2
线性探测如何优化,以加速探测速度。
二分查找及其变种 O ( log 2 n ) O(\log_2 n) O ( log 2 n )
示例:int ar[10]={1, 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10};{ 10,1,2,3,4,5,6,7,8,9};k个数据元素:如k = 3;输出{8,9,10,1,2,3,4,5,6,7}
实现函数:Right_Move_Array; // 右移一个数据元素Right_Move_Array_K; // 右移k 个数据元素Left_Move_Array;Left_Move_Array_K;
https://blog.csdn.net/weixin_45007066/article/details/116057402 https://blog.csdn.net/weixin_45332776/article/details/116333199
my_memset()
1 2 3 4 5 6 7 8 9 void my_memset (void * src, int val, int size) { assert(src != nullptr); char * cp = (char *)src; for (int i = 0 ;i < size;++i,++cp) { *cp = 0 ; } }
my_memmove()
my_atoi()
字符串数字转换为整型数字
"123"=>123"-123"=>-123"0123"(8进制)=>"0x123Df"=>"75894235702389573478903242334537" =>“505"错写为了"5o5”,要有纠错能力转为505