C语言_数组入门及练习
本章内容:
- 一维数组的定义和初始化
- 一维数组在内存中的存储
- 一维数组的使用
- 一维数组的应用实例
- 二维数组的定义和初始化
- 二维数组在内存中的存储
- 二维数组的使用
- 二维数组的应用实例
数组的定义和初始化
数组是包含给定类型的一组数据,并将这些数据依次存储在连续的内存空间中。每个独立的数据被称为数组的元素(element)。元素的类型可以是任意类型。 数组本身也是一个结构,其类型由它的元素类型延伸而来。更具体地说,数组的类型由元素的类型和数量所决定。如果一个数组的元素是 T 类型,那么该数组就称为“T 数组”。例如,如果元素类型为 int,那么该数组的类型就是“int 数组”。然而,int 数组类型是不完整的类型,除非指定了数组元素的数量。如果一个 int 数组有 16 个元素,那么它就是一个完整的对象类型,即“16 个 int 元素数组”。
一维数组的定义和初始化
数组的定义决定了数组名、元素类型以及元素个数。
其语法如下:<类型> 数组名 [ <元素数量> ];
元素数量在方括号[ ]之间,它必须是大于0的整型常量表达式。
1 |
|
总结
数组的类型有数组元素的类型、数组元素的个数。数组的元素个数可以通过sizeof 计算得到。
不同C标准
C99可以拿将要用键盘输入的变量作为方括号内的常量,但VS这样的C11不可以。
1 | int n=0; |
数值在内存的表
1 | int main() |
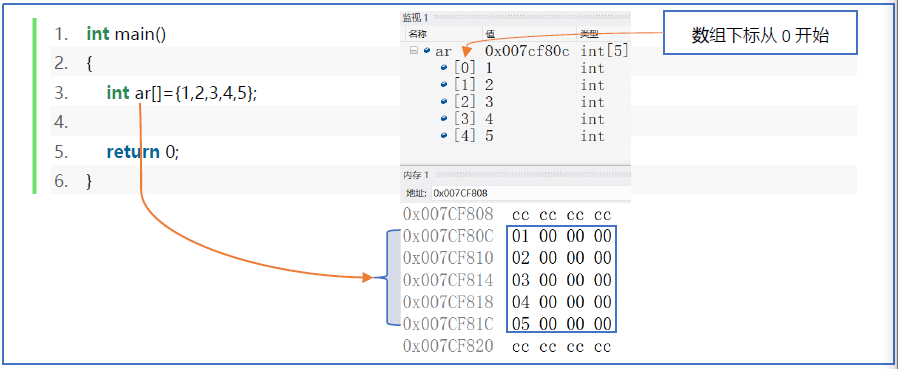
一维数组
一维数组的使用
数组在存储单元中是顺序连续存放的,任何一个元素都可以单独访问,其标识方法是用数组名和下标;
数组名[整型表达式];
整型表达式可以是变量,也可是常量,但必须是整型类型。
数组的访问(读取,写入)与数组的定义不一样。
1 | int main() |
1 | //为了便于代码的维护 |
const关键字在编译时期的替换是对于cpp文件而言的。对于.c文件,const就不适用了!
1 | const int m;//无意义 |
其他类型的数组
常性数组
1 | const int ar[5]={1,2,3,4,5};//常性数组,数组元素的值只可读,不可写。 |
存放字符(串)的数组
1 |
|
存放指针的数组
1 | int main() |
一维数组的应用实例
查表法
查表法是将一些事先计算好的结果,存储在常量数组中,用到是直接按下标取数据,以节省运行时的计算时间。是以空间换时间。
1 | //斐波那契数列 |
二维数组
二维数组的定义
二维数组的逻辑和物理(内存)表示
二维数组的使用
数组与函数
一维数组作为函数的实参
二维数组作为函数的实参
有关指针
int *p[n]
int (*p)[n]
对比
不同C标准
- C99可以拿将要用键盘输入的变量作为方括号内的常量,但VS这样的C11不可以。
1 | int n=0; |
- const关键字在编译时期的替换是对于cpp文件而言的。对于.c文件,const就不适用了!
练习
把ar数组中的数据赋值给br数组
1 | int main() |
1 | //头文件是#include <string.h>,如果要从数组a复制k个元素到数组b,可以这样做 |
为什么数组的下标从0 开始而不是从1 开始
https://blog.csdn.net/every__day/article/details/83114080
从数组中存储的数据模型来看,下标最精确的意思是”偏移量“,a[0]的偏移量是0,即为首地址。a[i]的偏移量是i,寻址公式就是a[i]_address = base_address + i*data_type_size
如果下标从1开始,那对应的寻址公式a[i]_address = base_address + (i-1) * data_type_size
对CPU来说,每次随机访问,就多了一次运算,多发一条指令。
如果希望数组的下标从1 到10 而不是从0 到9,该怎么做

用查表法实现日历的一些功能
随机函数给数组元素赋值并且排序
定义大小为100 的整型数组,使用随机函数给数组元素赋值。数值范围1..100,并且排序,使用冒泡排序实现。
随机函数:链接地址: http://www.cplusplus.com/reference/cstdlib/rand/
1 | void Bubble_Sort(int* br,int n) |
随机函数给数组元素赋值,不能重复
定义大小为100 的整型数组,使用随机函数给数组元素赋值。数值的范围是1 .. 100,并且不能重复。
1 | int* My_NonRepeating_RandArr(int* ar, int n) |
统计字符串中每个英文字符出现的次数,不区分大小写
统计字符串中每个英文字符出现的次数,不区分大小写,只统计英文字符。
统计字符串中每个英文字符出现的次数,区分大小写
统计字符串中每个英文字符出现的次数,区分大小写,只统计英文字符。
FindValue
FindValue,Value如果没在数组中则返回-1,如果在则返回下标。
1 | int FindValue(int* br, int n, int val) |
给超大数组随机赋值,不能重复,用哈希算法
如果第六题中数组大小改为1000000,那么数组开辟空间就很大,如果仍然按照旧的方式去做肯定是对程序不利的。考虑用哈希算法解决!
有序数组中FindValue,用二分查找
接第9题FindValue,如果我们的数组中的数据是按照大小顺序排列的,那么我们就不需要按顺序遍历查找,可以采取二分查找,何为二分查找,效率如何,如何二分查找?
二分查找的变种——斐波那契查找
二分查找及其变种:斐波那契查找的时间复杂度还是,但是与折半查找相比,斐波那契查找的优点是它只涉及加法和减法运算,而不用除法,而除法比加减法要占用更多的时间。