C语言_结构体
本章内容
- 结构体类型的设计
- 结构体变量初始化
- 结构体成员访问
- 结构体与数组
结构体类型的设计
C 语言提供了基本数据类型,如 char, short, int, float 等类型,我们称之为内置类型。
程序开发人员可以使用结构体来封装一些属性,设计出新的类型,在 C 语言中称为结构体类型。
在 C 语言中,结构体是一种数据类型。(由程序开发者自己设计的类型)
可以使用结构体(struct)来存放一组不同类型的数据。结构体的定义形式为:
1 | struct 结构体名 |
我们自己设计一个学生类型
客观事物(实体)是复杂的,要描述它必须从多方面进行,也就是用不同的数据类型来描述不同的方面。如学生实体可以这样来描述:
- 学生学号(用字符串描述)
- 学生姓名(用字符串描述)
- 性别(用字符串描述)
- 年龄(用整型数描述)。
这里用了2种不同数据类型,以及四个数据成员(data member)来描述学生实体。
(数据成员,也可称之为属性,不能称之为函数中的变量概念)

结构体变量的定义和初始化
既然结构体是一种数据类型,那么就可以用它来定义变量。结构体就像一个“模板”,定义出来的变量都具有相同的性质。
也可以将结构体比作“图纸”,将结构体变量比作“零件”,根据同一张图纸生产出来的零件的特性都是一样的。
结构体是一种数据类型,是创建变量的模板,不占用内存空间;结构体变量才包含了实实在在的数据,需要存储空间。
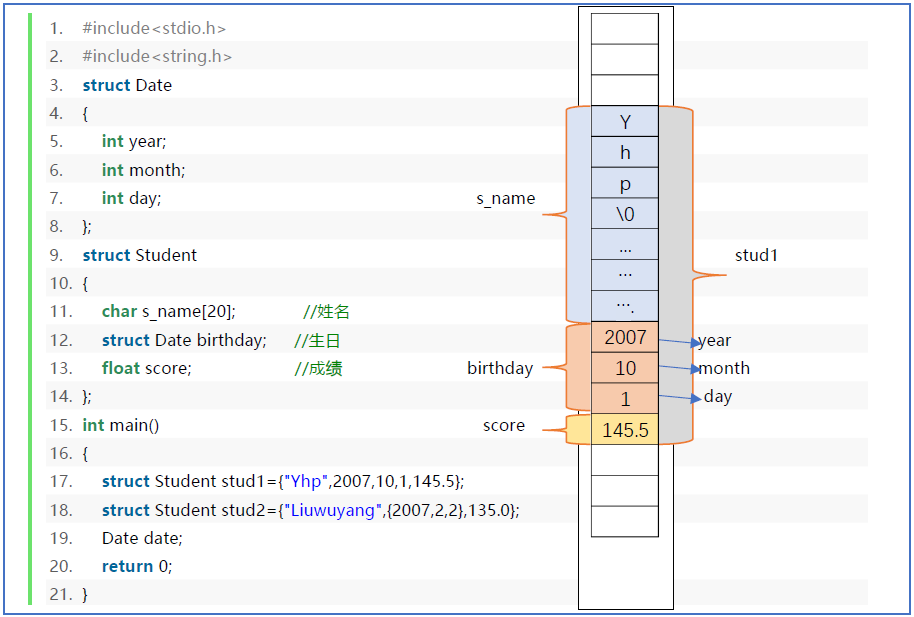
结构体变量在内存中表示
思考下述代码结构体在内存中的分配是A情况还是B情况?
1 | struct Student |
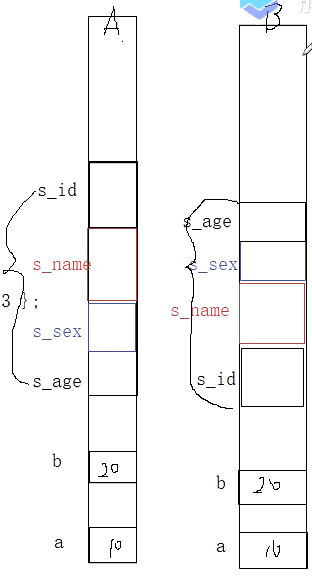
答案是A,即结构体成员的内存分布顺序是从上到下依次排列。为什么不是像a,b那样的顺序?
我自己的解释:结构体的类型结构声明不像函数中变量的声明定义。我们要区分类型内部的成员和函数内部的变量,两者是截然不同的!结构体类型的抽象是一种类型,是由若干其他类型组成的一种新类型,那么类型内部的成员必然要按照我们在定义时的顺序从上到下分布内存空间,才符合程序设计的逻辑思路。按照如此规则如此分布,才能方便我们进行后续的给结构体变量初始化赋值,大括号内的值的顺序是按照成员顺序来的,而不是随意颠倒顺序,编译器是不会同意的。
示例
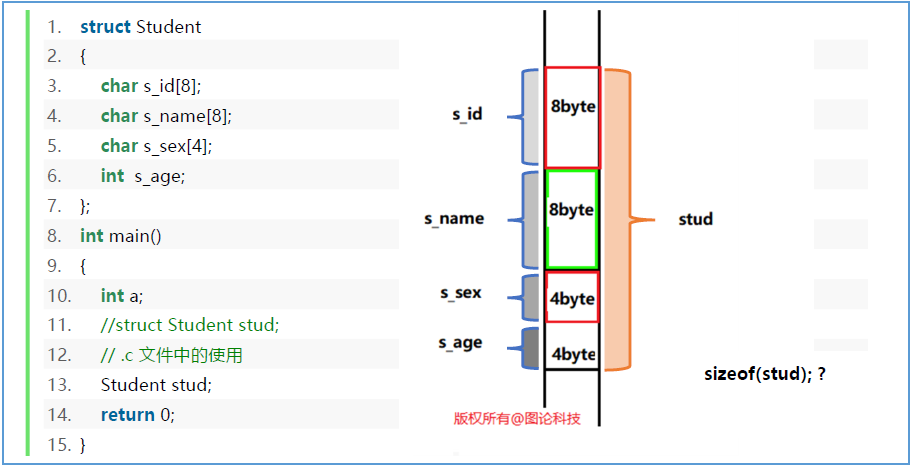
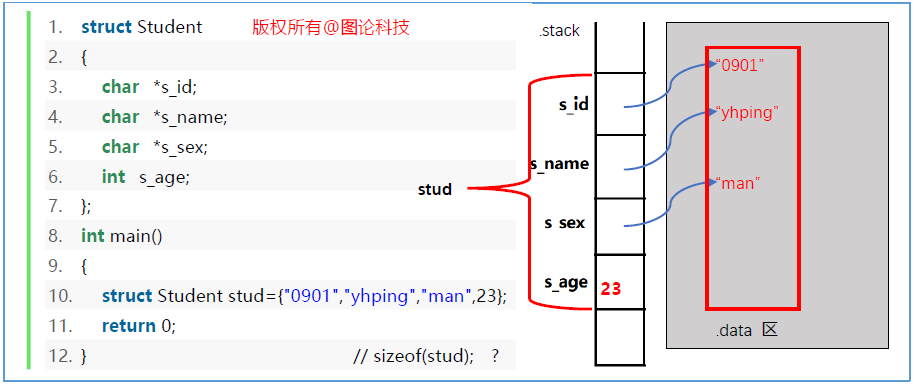
如果把char数组改为指针:
结构变量初始化

大括号内的值的顺序是按照成员顺序来的,而不是随意颠倒顺序,编译器是不会同意的。
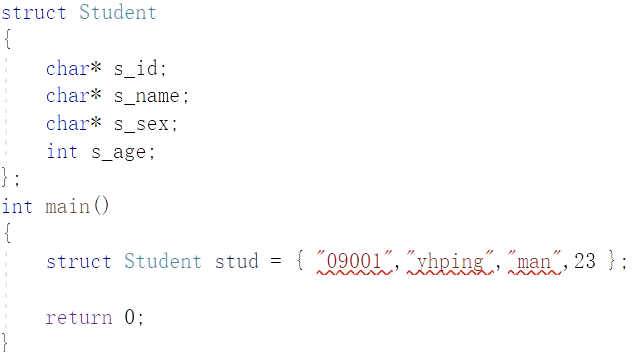
如果把char数组改为指针:
这时按照上图的赋值方式,在VS2019中是不能通过的,因为,"09001"这种双引号引起来的字符串的类型是常量字符串型即const char*(要给s_id赋的值本质是字符串首字符'0'的指针,此指针只能读数据不能改数据,因此类型是const char*),与我们在结构体中声明的char*不匹配。
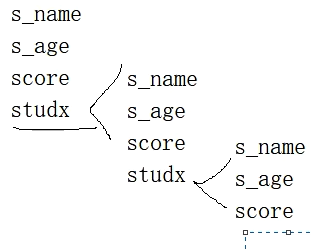
结构体嵌套结构体
思考以下结构是否可行?
1 | struct Student |
结构体链接结构体
1 | struct Student |
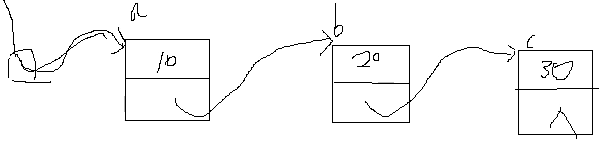
如何使用循环打印?
1 | void Print_List(const struct Node* head) |
结构体成员的访问
结构体变量的成员使用.访问。
获取和赋值结构体变量成员的一般格式为:结构体变量.成员名;
结构体变量成员的访问
1 |
|
结构体变量(的成员)的赋值
对结构变量整体赋值有三种情况:
- 定义结构体变量(用{ }花括号初始化);
- 用已定义的结构变量初始化;
- 结构体类型相同的变量可以作为整体相互赋值。
在其他情况的使用过程中只能对成员逐一赋值。
在 C 语言中不存在对结构体类型的强制转换(和内置类型的区别)。
1 | struct Student |
关于两结构体变量整体赋值如何实现
首先,抓住两个结构体变量各自的地址,再依次同步迭代拷贝,调用的函数是memcpy();如memcpy(&stdb,&stda,sizeof(stda));
关于上面提到的错误赋值
stdx.s_name = stda.s_name;此语句是错误的。`
为什么?
s_name是一个数组,数组是不可能给另一个数组直接赋值的。因为:s_name代表首元素指针,根据我们数组那一节的知识储备,这个指针是常量(即数组名所代表的指针),stdx.s_name = stda.s_name这个语句的意思是把stda.s_name这个指针赋给stdx.s_name这个指针,这显然是不可行的,数组首元素指针不可能改变!
同理,数组名不可以++,如已知int ar[100]={};的ar数组,ar++这个语句是错误的。
应该对数组进行全部迭代拷贝,如调用strcpy_s(stdx.s_name,stda.s_name);
与数组{}花括号赋值的异同
不同点是:数组的花括号内的值类型必须一致,而结构体花括号内的值可能不一致。
共同点:如果{}花括号内的内容缺省,默认赋值为0。
结构体变量和函数
拿打印函数举例

二个打印函数那个好 ? 原因是什么?

二个打印函数那个好 ? 原因是什么?和指针比较的优势? 限制条件是什么?
肯定是Print_c好。优势在于如果不是用指针来传值,那么还要再次开辟空间且给形参复制源变量的信息,导致空间和时间的效率都大大降低。而用指针来传值,直接能操作源变量。而用const来读取信息更为谨慎,因为const能保证该指针只能读取变量信息而不能改变变量信息。
结构体的大小
1 | struct Node_a |
为什么要理解字节对齐问题
- 内存大小的基本单位是字节,理论上来讲,可以从任意地址访问变量,但是实际上,cpu并非逐字节读写内存,而是以 2, 4 或 8 的倍数的字节块来读写内存,因此就会对基本数据类型的地址作出一些限制,即它的地址必须是 2,4 或 8 的倍数。那么就要求各种数据类型按照一定的规则在空间上排列,这就是对齐。
- 有些平台每次读都是从偶地址开始,如果一个 int 型(假设为 32 位系统)如果存放在偶地址开始的地方,那么一个读周期就可以读出这 32 bit,而如果存放在奇地址开始的地方,就需要 2 个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该 32 bit 数据。显然在读取效率上下降很多。
- 由于不同平台对齐方式可能不同,如此一来,同样的结构在不同的平台其大小可能不同,在无意识的情况下,互相发送的数据可能出现错乱,甚至引发严重的问题。
计算规则
由于存储变量地址对齐的问题,计算结构体大小的 3 条规则:
-
结构体变量的首地址,必须是结构体变量中的“最大基本数据类型成员所占字节数”的整数倍。
-
结构体变量中,相对于结构体首地址,每个成员的偏移量,都是成员本身基本数据类型所占字节数的整数倍。
1
2
3
4
5
6struct Node
{
char ca;//偏移地址为0,占1字节。偏移地址1-7起地址对齐占位作用,内容无实际意义。
double dx;//偏移地址为8,占8字节。因为要满足原则2即double的偏移量要相对于结构体首地址(视为0),是成员本身基本数据类型所占字节数的整数倍。只有在偏移地址8时,才满足(8-0)/8==1。
char cb;
};//24 -
结构体变量的总大小,为结构体变量中 “最大基本数据类型成员所占字节数”的整数倍。

实例/测验
1 | struct node |
1 | struct sdate |
1 | struct Inventory |
1 | struct Employee |
如何巧妙计算偏移量
有Employee类型的结构体,成员有name, address, zip, telenum, salary等,现要求:不要定义任何结构体变量计算zip相对结构体自身首地址的偏移量。
利用宏+无中生有法。
1 |
|
#pragma pack指定对齐值
预处理指令#pragma pack(n)可以改变默认对齐数。n取值是 1, 2, 4, 8, 16。
VS 中默认值 = 8,gcc 中默认值 = 4
1 |
|
终极总结
- 结构体变量的首地址,必须是
MIN{"结构体 最大基本数据类型成员 所占字节数", 指定对齐方式}的整数倍。 - 结构体中,相对于结构体首地址,每个成员的偏移量,都是
MIN{该基本数据类型成员, 指定对齐方式}的整数倍。 - 结构体的总大小,为
MIN{结构体最大基本数据类型成员所占字节数, 指定对齐方式}的整数倍。
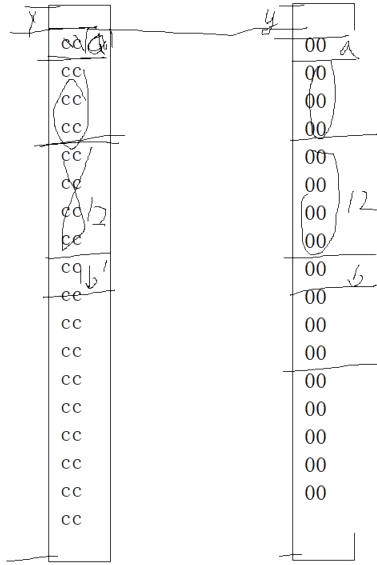
比较结构体变量
不要轻易地使用memcmp函数来对比两个结构体变量。因为结构体内存结构层面中,成员间的空隙填充的内容是不可控的,即结构体是一种非连续型内存空间。
1 | struct Node |
结构体与数组
所谓结构体数组,是指数组中的每个元素都是一个结构体类型。在实际应用中,C 语言结构体数组常被用来表示一个拥有相同数据结构的群体,比如一个班的学生、一个公司的员工等。
联合体
联合体(union)与结构体(struct)有一些相似之处。但两者有本质上的不同。在结构体中,各成员有各自的内存空间。而在联合体中,各成员共享同一段内存空间, 一个联合体变量的长度等于成员中最长的长度。
应该说明的是, 这里所谓的共享不是指把多个成员同时装入一个联合变量内, 而是指该联合变量可被赋予任一成员值,但每次只能赋一种值, 赋入新值则冲去旧值。
一个联合体类型必须经过定义之后, 才能使用它,才能把一个变量声明定义为该联合体类型。
联合体不仅可以节省内存空间,最本质、重要的用法是对同一段空间采取不同的类型格式去识别、读取数据。
1 | union Node |
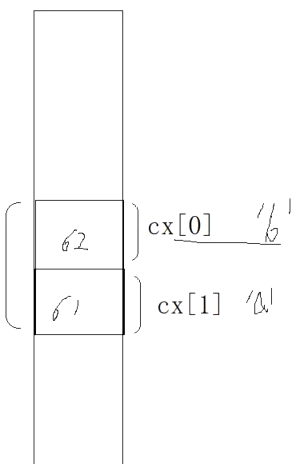
声明和定义时的注意
设计有名的联合体,同时没有定义变量。
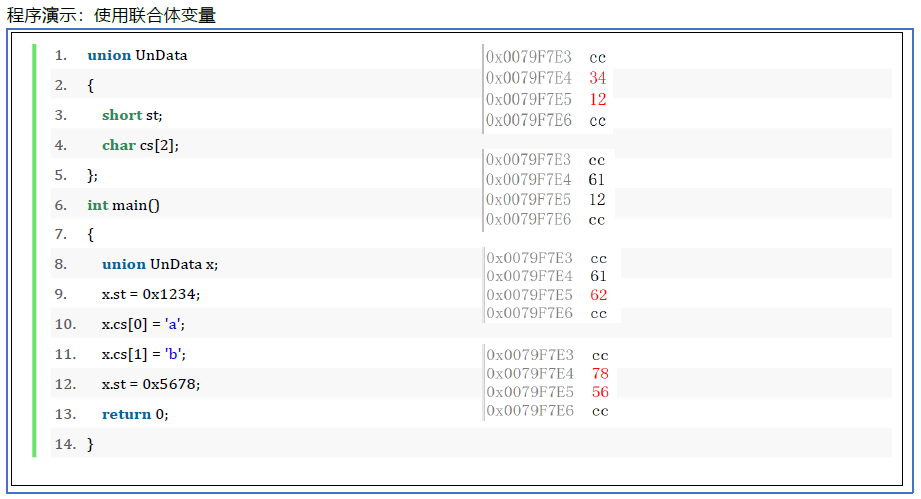
1 | union UnData |
设计有名的联合体,同时定义变量。与上述代码等效,节省了一行代码。
1 | union UnData |
设计无名的联合体,同时定义变量。这样是可行的。
1 | union |
但要注意的是,如下做法编译器是不认为x,y属于同一种类型的联合体的。
1 | union |
当然,我们可以用typedef关键字把无名的联合体定义出的变量名赋予其类型的性质。
1 | typedef union |
重要的面试笔试题目
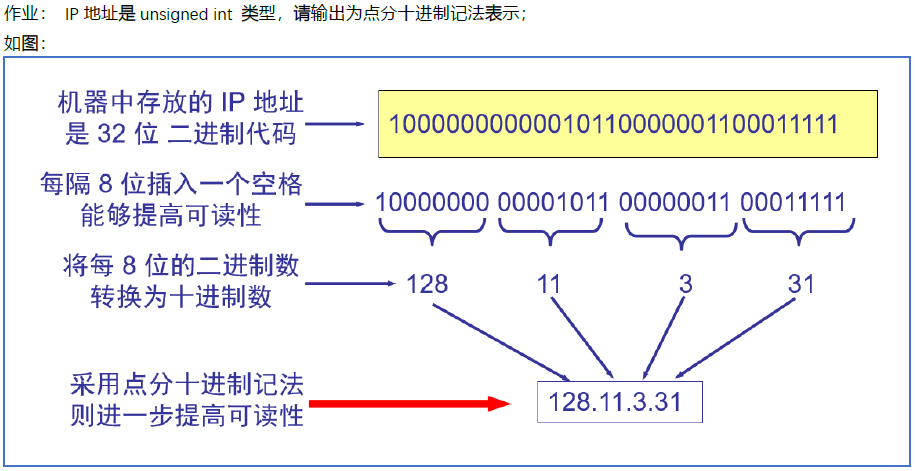
IP地址本质上是一串32位二进制代码(对于ipv4是32位,ipv6是128位),可看作无符号int数。题目要求把32位二进制代码的每八位转换为一个无符号十进制数,并用“点”隔开,最终转为字符串。同时也要求把该格式的字符串能逆转换为32位二进制代码构成的无符号int数。
要运用到的输入/输出函数
1 | char buff[20]; |
1 | scanf();//从标准输入设备stdin中输入的数据读取值。 |
代码编写
1 | union IPNode |
1 | unsigned int str_to_int(const char* buff) |
作业
-
给结构体变量赋值和输出结构体变量的值。想尽办法做初始化。
