Linux_正则表达式
正则表达式
Regular Expression
主要参考文档:
https://legacy.cplusplus.com/reference/regex/ECMAScript/
[[Linux_Shell编程#结合正则表达式的示例]]:case的示例中
1 | [][][]代表三个字符。 |
Quantifiers(*、+、?、{n})
量词
代表通用的信息的部分。
*:可能有(0到无数个)前导字符。*只是指示符,本身不参与,指示前面的字符会重复0到无数次。+:最少1个前导字符。?:只有1个前导字符。{n}:有n个前导字符。{n,}:有大于等于n个的前导字符。{min,max}:至少有min个,但不超过max个(左闭右开)
Special Pattern Characters([])
特殊模式字符
.:匹配任意单个字符[...]:匹配[]中包含的任意字符。- 比如
[1234567890]或[0-9]都表示:字符0到9 [A-Z]表示大写字母[A-Za-z]表示大小写字母。- 分类字符,见《Character classes(字符类)》一节
- 比如
\s:表示空格字符,空格、制表符都可以。(可替代[[:space:]])
更多特殊字符见手册。
https://legacy.cplusplus.com/reference/regex/ECMAScript/
.*表示所有字符。
Character classes
字符类
[:alpha:]:表示所有字母grep '[[:alpha:]]' file.txt
[:digit:]:表示数字[:alnum:]:表示字母+数字^[:alpha:]:表示除了字母以外grep '[^[:alpha:]]' file.txt
Assertions(^、$)
断言
^:出现在行首的指定字符串。- 注意,在
[]内外,^表达的意思是不一样的。- 在
[]内,表示“非” - 在
[]外,才表示“首” - 对于分类字符(比如
[:alpha:]),需要放到两层[]之内,分类字符的[]之外,即:[^[:alpha:]]。
- 在
- 注意,在
$:出现在行尾的指定字符串。
Alternatives(或关系:|)


找出带A或带B的行。
相当于求了两次grep,结果合在一起。
注意|需要转义。
Groups
组

核心概念:分组的作用
- 将量词应用于字符序列: 这是最基本的作用。想象你要匹配多次出现的单词“hello”而不是单个字母“l”多次。你需要把“hello”当成一个整体来量化。
- 错误示例:
hel{2,}o:这个匹配的是 ‘he’ + 至少2个’l’ + ‘o’, 可以匹配 “hello”, “hellllo”,但不能匹配 “hellohello” (两个hello连在一起)。 - 正确示例:
(hello){2,}:这个匹配的是 "(hello)"这个整体 至少出现2次,可以匹配 “hellohello”, “hellohellohello” 等。
- 错误示例:
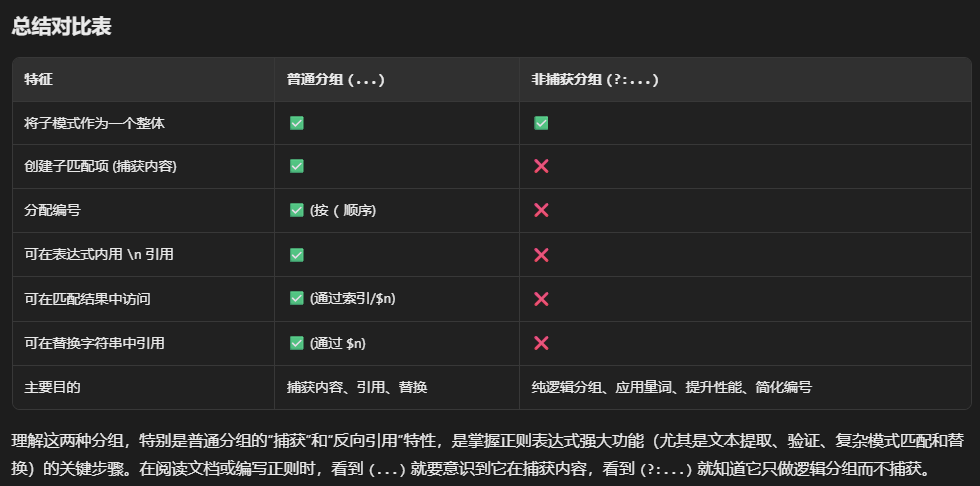
- 创建子匹配项(反向引用): 这是普通分组
(subpattern)独特且强大的功能。它不仅仅是匹配,还会记住分组内匹配到的具体内容,并分配一个编号(按照左括号(出现的顺序)。这些被记住的内容称为“子匹配项”或“捕获组”。
普通分组(分组且捕获):(subpattern)
- 将
subpattern作为一个整体单元进行操作(特别是应用量词)。 - 捕获
subpattern匹配到的实际文本内容。 - (重要)创建反向引用(在同一个正则表达式内部,用
\1,\2,\3… 来指代第1、2、3…个分组捕获的内容)。 - 在正则匹配结果中,可以通过索引(如 C++ 的
smatch[1],smatch[2])获取每个子匹配项的值。 - 在替换操作中,可以通过类似
$1,$2,$3… 的语法来引用这些子匹配项。
示例1:匹配重复的单词或连续字母
1 | 正则: (\w+)\s+\1 |
示例2:提取日期各部分(年、月、日)
1 | 正则: (\d{4})-(\d{2})-(\d{2}) |
被动/非捕获分组:(?:subpattern)
作用
- 将
subpattern作为一个整体单元进行操作(应用量词)。 - 不会捕获匹配到的文本内容。
- 不会创建子匹配项。
- 不分配分组编号(因此不会影响其他普通分组的编号)。
- 无法在正则表达式内部用
\n反向引用。 - 无法在匹配结果或替换操作中单独访问。
为什么需要它?
- 性能: 如果不关心分组内容,避免捕获可以提高效率(尤其是在大量重复匹配时)。
- 简化编号: 当你只想分组应用量词,但又不想这个分组计入编号体系、干扰你真正关心的捕获组(普通分组)时。它让后续普通分组的编号更清晰。
- 避免不必要的内存开销: 不用存储不关心的匹配文本。
示例:匹配文件扩展名(但只关心扩展名本身)
1 | 目标:从 "report.txt", "data.csv.zip", "image.png" 中提取扩展名 (txt, zip, png) |
示例2:应用量词但不捕获(纯粹为了结构)
1 | 匹配连续出现的 "hello" 或 "world" 两次 |
总结
grep
Get Regular Expression Print
*
1 | echo "AAAA" > aa.txt |
1 | grep B* aa.txt |
结果:
1 | AAAA |
如上结果,因为B*代表前面的B可能会出现0到n次。所以,AAAA也匹配上了。
1 | grep BB* aa.txt |
结果:
1 | BB |
如上结果,这次没出现AAAA,因为我们限制了BB*,即第一个字符必须是B后面可能出现0到n个B。可以用B+替代上述语义:+。
因此*还是要慎用,能代表的范围太大了。
+
类似于*,区别是1到n次。排除了0次的可能。
1 | grep 'B\+' aa.txt |
需要转义,并在单引号中使用。
结果:
1 | BB |
示例1
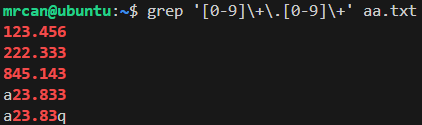
1 | echo "123.456" >> aa.txt |
怎么提取出.前后全是数字的行?
1 | grep '[0-9]\+\.[0-9]\+' aa.txt |
以上命令表示:
\.是转义,意思是中间有个..前面有最少1个0到9的字符.后面有最少1个0到9的字符
结果:
示例2 - 精确指示n个字符
需要用到{},注意在单引号中,{和}均需转义。
指示有4个A到Z字符。
1 | grep '[A-Z]\{4\}' aa.txt |
结果:AAAA
指示有大于等于2个的A到Z字符。在右括号前加,
1 | grep '[A-Z]\{3,\}' aa.txt |
结果:
1 | AAAA |
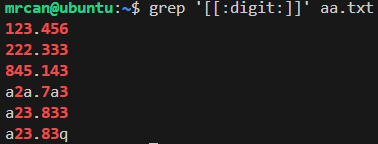
结合分类字符(如[:alpha:])
注意外面还需要加一层[]
想找到文件中带数字的行:
1 | grep '[[:digit:]]' aa.txt |
想找到文件中带字母的行:
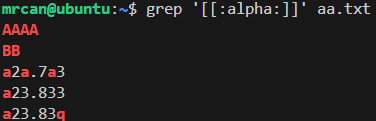
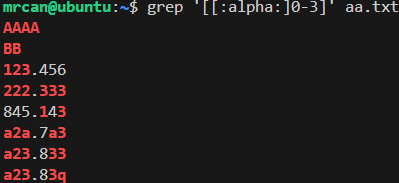
想找到文件中带字母或有0到3字符的行:
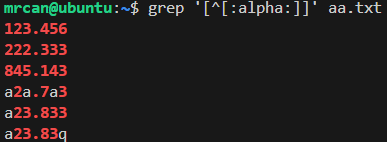
想找到文件中有非字母字符的行:
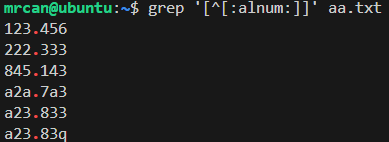
想找到文件中有非字母、非数字字符的行:
?
只出现了1次前面的字符。
$
以什么字符结尾。
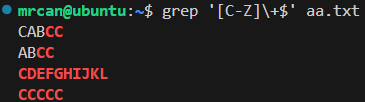
1 | grep '[C-Z]\+$' aa.txt |
表示:结尾最少有1个C到Z的字符。
如果aa.txt的内容是:
1 | AAAA |
则执行grep '[C-Z]\+$' aa.txt的结果:
既以…为开头,又以它为结尾?
1 | grep '^[C-Z]\+$' aa.txt |
我原先想的是,这个命令表示既以至少1个C到Z的字符开头,又以至少1个C到Z的字符结尾。(错误解释!)
让Deepseek分析后,不是这样解释的。而是:
正则表达式 ^[C-Z]\+$ 要求:
- 整行必须完全由 C-Z 的大写字母组成(字母必须 ≥ C)
- A和B字母不被允许
- 无任何数字/符号/小写字母
因此,如果aa.txt的内容是:
1 | AAAA |
则执行grep '^[C-Z]\+$' aa.txt的结果:

表达式拆解与执行逻辑
-
^锚点(行首)- 强制匹配必须从行首开始
-
[C-Z]+\+组合[C-Z]只匹配 单个 C-Z 范围内的大写字母\+表示前面的[C-Z]至少出现一次(可以出现多次)- 关键效果:每一个位置都需匹配
[C-Z]
(不能是空格/数字/小写字母/其他字符)
-
$锚点(行尾)- 强制匹配必须延伸到行尾结束
强制约束的逻辑链
当正则引擎执行 ^[C-Z]\+$ 时,它的匹配规则如下:
- 从行首 (
^) 开始检查第一个字符
→ 必须是C-Z的大写字母 - 继续检查后续字符
→ 因为\+要求连续多个匹配,所以第二个字符必须也是C-Z的大写字母
→ 第三个、第四个…所有字符都必须满足 - 直到遇见行尾 (
$)
→ 此时整行已被完全匹配
✨ 核心机制:
[C-Z]\+作为连续的整体充当了 “填充内容” 的角色,它从行首一直延伸到行尾,不允许中间插入任何非 C-Z 字符。
这种严格约束主要用于验证格式纯净的字符串,典型场景包括:
- 检测不含空格的英文单词(如
"PYTHON") - 过滤无数字/符号的纯大写文本(如验证商品代码
"SKUXYZ") - 也可以有等效的、更简洁的形式:
grep -x '[C-Z]\+' aa.txt(-x表示整行匹配)
awk
Alfred Aho, Peter Weinberger, Brian Kernighan

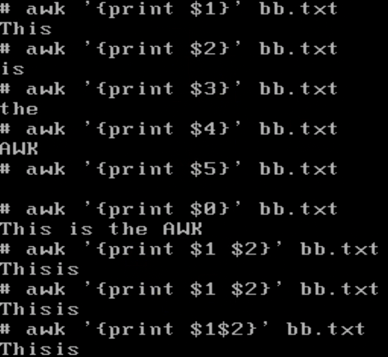
grep是扫描每一整行的,按行为单位。而awk是按一行中的每个字段为单位查询的,类似于excel表格,可以切分各个字段。即可以按列操作。
结合正则表达式
在 awk命令中,
/tty/中的/(正斜杠) 是正则表达式(Regular Expression)的定界符。它表示中间的内容(tty)是一个需要匹配的模式。
1 | awk '/tty/{print $0}' ps.txt |
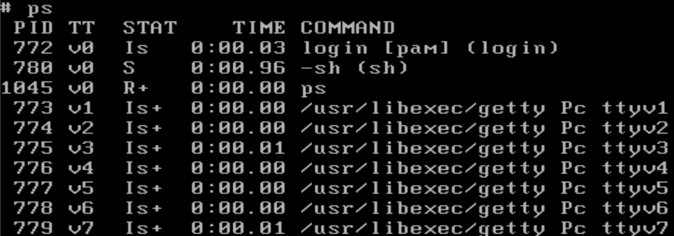
假如ps.txt文件内容如上,我们想找到字段有tty的字段。
则,在awk命令后面先用单引号' '包裹,再在里面写斜杠/ /包裹正则表达式。后半部分再用大括号{ }包裹要进行的打印操作。
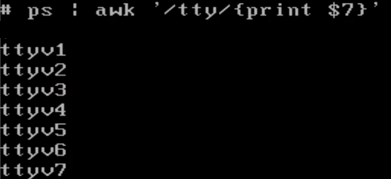
print可以自定义内容
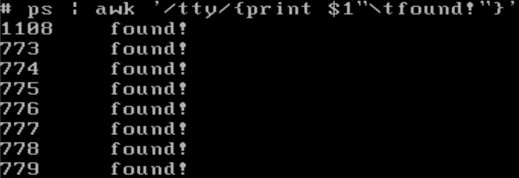
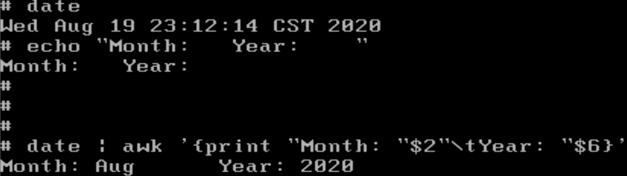
可以用printf进行格式化输出
ps内容:
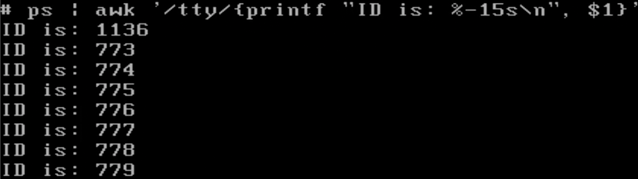
单独指定匹配每一行的第n列,其他列跳过
employees文件内容:

形式:
1 | awk '$2~/^[A-z][a-z]+/ {print $1}' employees |
即,在' '内的前面加一个第几列$2和波浪号~。
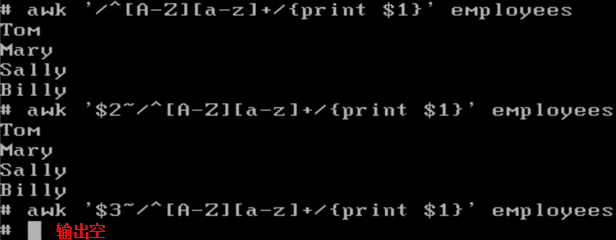
第一句awk的意思是搜索每一行的所有列,查找以大写字母开头,后面至少有一个小写字母。匹配到后,打印该行的第1列。
第二句awk的意思是只搜索每一行的第2列,查找以大写字母开头,后面至少有一个小写字母。匹配到后,打印该行的第1列。
第二句awk的意思是只搜索每一行的第3列,查找以大写字母开头,后面至少有一个小写字母。匹配到后,打印该行的第1列。由于第三列全是数字,没有匹配到符合条件的行,所以打印空。
可以在{}中对文件信息进行修改
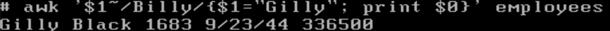
以上语句的意思:找每一行的第1列中含Billy的,之后,把该行第1列修改为Gilly。之后,打印匹配到的所有行。
在单引号中,内置了数字大小比较器
ps内容:
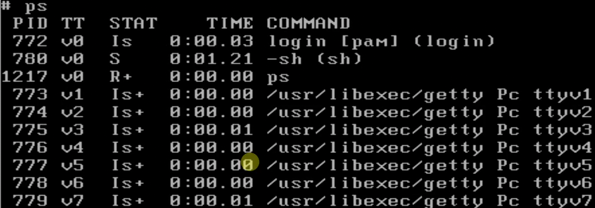
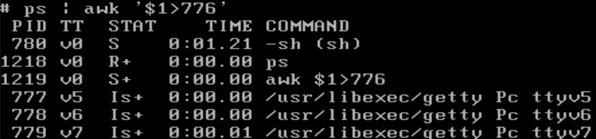
我们想要输出所有PID大于776的:
可以在awk后的' '单引号内写$1>776,它内置了把字符串转换为数字之后比较的操作,之后帮我们筛选出符合条件的。
甚至还可以在里面写一些简单的运算:('$1>776+1')
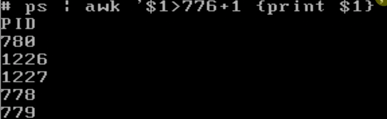
sed
Stream Editor
用于处理流。把字符串、文件按流的方式处理。流的特点是只能单向,不能后撤。