外观模式是一种使用频率非常高的结构型设计模式 ,它通过引入一个外观角色来简化客户端与子系统之间的交互,为复杂的子系统调用提供一个统一的入口,降低子系统与客户端的耦合度 ,且客户端调用非常方便。
不知道大家有没有比较过自己泡茶和去茶馆喝茶的区别,如果是自己泡茶需要自行准备茶叶、茶具和开水,如图所示。
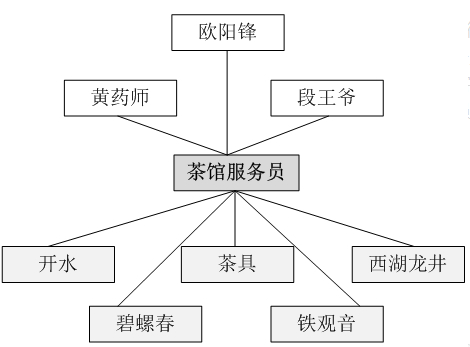
而去茶馆喝茶,最简单的方式就是跟茶馆服务员说想要一杯什么样的茶。正因为茶馆有服务员,顾客无须直接和茶叶、茶具、开水等交互,整个泡茶过程由服务员来完成,顾客只需与服务员交互即可,整个过程非常简单省事,如图所示。
在软件开发中,有时候为了完成一项较为复杂的功能,一个客户类需要和多个业务类交互,而这些需要交互的业务类经常会作为一个整体出现,由于涉及到的类比较多,导致使用时代码较为复杂,此时,特别需要一个类似服务员一样的角色,由它来负责和多个业务类进行交互,而客户类只需与该类交互 。
外观模式通过引入一个**外观类(Facade)**来实现该功能,外观类充当了软件系统中的“服务员”,它为多个业务类的调用提供了一个统一的入口,简化了类与类之间的交互。
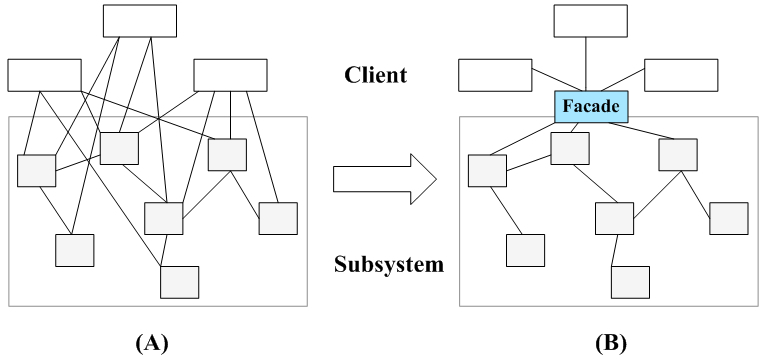
在外观模式中,那些需要交互的业务类被称为子系统(Subsystem) 。如果没有外观类,那么每个客户类需要和多个子系统之间进行复杂的交互,系统的耦合度将很大。而引入外观类之后,客户类只需要直接与外观类交互,客户类与子系统之间原有的复杂引用关系由外观类来实现,从而降低了系统的耦合度,如图所示。
外观模式中,一个子系统的外部与其内部的通信通过一个统一的外观类进行,外观类将客户类与子系统的内部复杂性分隔开,使得客户类只需要与外观角色打交道,而不需要与子系统内部的很多对象打交道。
外观模式:为子系统中的一组接口提供一个统一的入口。外观模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
外观模式又称为门面模式,它是一种对象结构型模式。外观模式是迪米特法则的一种具体实现 ,通过引入一个新的外观角色可以降低原有系统的复杂度,同时降低客户类与子系统的耦合度。
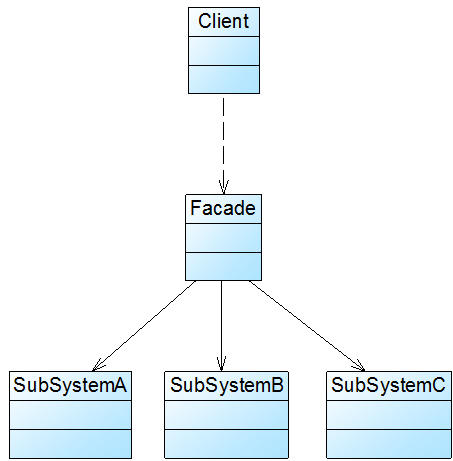
外观模式没有一个一般化的类图描述。下图可以简单地描述外观模式的结构:
外观模式包含如下两个角色:
Facade(外观角色)
在客户端可以调用它的方法
在外观角色中可以知道相关的(一个或者多个)子系统的功能和责任;
在正常情况下,它将所有从客户端发来的请求委派到相应的子系统去,传递给相应的子系统对象处理。
SubSystem(子系统角色)
在软件系统中可以有一个或者多个子系统角色,每一个子系统可以不是一个单独的类,而是一个类的集合,它实现子系统的功能;
每一个子系统都可以被客户端直接调用,或者被外观角色调用,它处理由外观类传过来的请求;
子系统并不知道外观的存在,对于子系统而言,外观角色仅仅是另外一个客户端 而已。
外观模式的主要目的在于降低系统的复杂程度,在面向对象软件系统中,类与类之间的关系越多,不能表示系统设计得越好,反而表示系统中类之间的耦合度太大,这样的系统在维护和修改时都缺乏灵活性,因为一个类的改动会导致多个类发生变化。
而外观模式的引入在很大程度上降低了类与类之间的耦合关系,增加新的子系统或者移除子系统都非常方便,客户类无须进行修改(或者极少的修改),只需要在外观类中增加或移除对子系统的引用即可。从这一点来说,外观模式在一定程度上并不符合开闭原则,增加新的子系统需要对原有系统进行一定的修改,虽然这个修改工作量不大。
外观模式中所指的子系统是一个广义的概念,它可以是一个类、一个功能模块、系统的一个组成部分或者一个完整的系统。子系统类通常是一些业务类,实现了一些具体的、独立的业务功能,其典型代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class SubSystemA { public : void MethodA () { } }; class SubSystemB { public : void MethodB () { } }; class SubSystemC { public : void MethodC () { } };
在引入外观类之后,与子系统业务类之间的交互统一由外观类来完成,在外观类中通常存在如下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Facade { private : SubSystemA * obja; SubSystemB * objb; SubSystemC * objc; public : Facade () { obja = new SubSystemA (); objb = new SubSystemB (); objc = new SubSystemC (); } void Method () { obja->MethodA (); objb->MethodB (); objc->MethodC (); } };
由于在外观类中维持了对子系统对象的引用,客户端可以通过外观类来间接调用子系统对象的业务方法,而无须与子系统对象直接交互。引入外观类后,客户端代码变得非常简单,典型代码如下:
1 2 3 4 5 int main () Facade facade = new Facade (); facade->Method (); }
下面通过一个应用实例来进一步学习和理解外观模式。
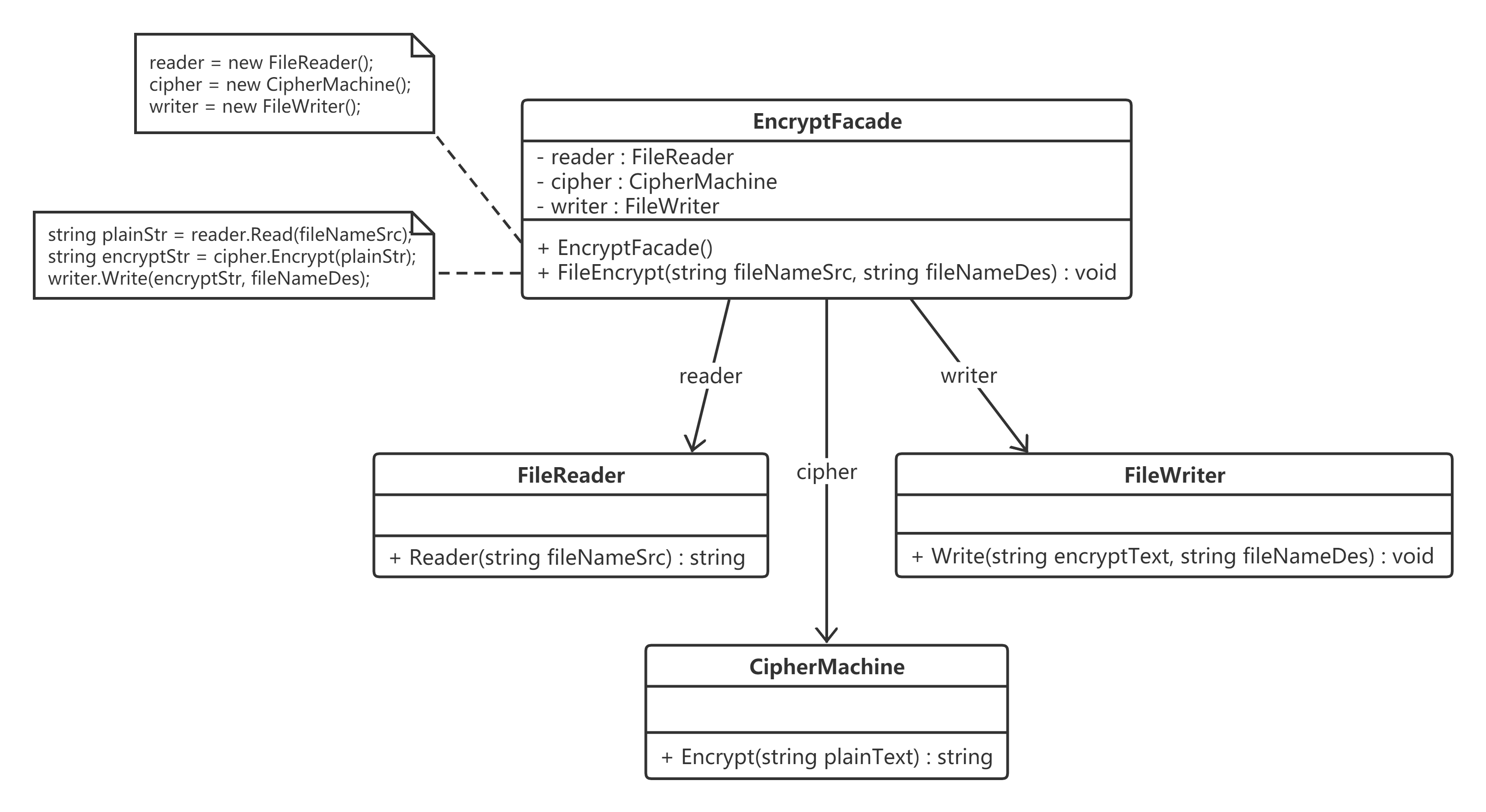
某软件公司欲开发一个可应用于多个软件的文件加密模块,该模块可以对文件中的数据进行加密并将加密之后的数据存储在一个新文件中,具体的流程包括三个部分:读取源文件、加密、保存加密之后的文件 。其中,读取文件和保存文件使用流来实现,加密操作通过求模运算实现。这三个操作相对独立,为了实现代码的独立重用,让设计更符合单一职责原则,这三个操作的业务代码封装在三个不同的类中。
现使用外观模式设计该文件加密模块。
通过分析,本实例结构图如下。
图中,EncryptFacade充当外观类,FileReader、CipherMachine和FileWriter充当子系统类。
文件读取类,充当子系统类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #ifndef FILEREADER_H #define FILEREADER_H #include <iostream> #include <fstream> #include <sstream> using namespace std;class FileReader { public : string Read (const string & fileNameSrc) { cout << "读取文件,获取明文。" << endl; fstream fs (fileNameSrc.c_str(), ios_base::in) ; stringstream ss; string s; if (fs.is_open ()) { while (fs >> s) { ss << s; } } else { cout << "不能打开文件!" << endl; } return ss.str (); } }; #endif
数据加密类,充当子系统类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #ifndef CIPHERMACHINE_H #define CIPHERMACHINE_H #include <iostream> #include <string> #include <vector> using namespace std;class CipherMachine { public : string Encrypt (const string & plainText) { cout << "数据加密,将明文转换为密文!" << endl; string es = "" ; vector<char > vc (plainText.begin(), plainText.end()) ; for (auto & c : vc) { es += (c % 36 ) + 65 ; } cout << es << endl; return es; } }; #endif
文件保存类,充当子系统类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #ifndef FILEWRITER_H #define FILEWRITER_H #include <fstream> #include <iostream> #include <sstream> using namespace std;class FileWriter { public : void Write (const string & encryptStr, const string& fileNameDes) { cout << "保存密码,写入文件。" << endl; fstream fs (fileNameDes, ios_base::out) ; if (fs.is_open ()) { fs.write (encryptStr.c_str (), encryptStr.size ()); } else { cout << "文件写入失败!" << endl; } } }; #endif
加密外观类,充当外观类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #ifndef ENCRYPTFACADE_H #define ENCRYPTFACADE_H #include "ciphermachine.h" #include "filereader.h" #include "filewriter.h" #include <memory> class EncryptFacade { private : shared_ptr<FileReader> reader; shared_ptr<FileWriter> writer; shared_ptr<CipherMachine> cipher; public : EncryptFacade () { reader = make_shared <FileReader>(); cipher = make_shared <CipherMachine>(); writer = make_shared <FileWriter>(); } void FileEncrypt (const string & fileNameSrc, const string & fileNameDes) { string plainStr = reader->Read (fileNameSrc); string encryptStr = cipher->Encrypt (plainStr); writer->Write (encryptStr, fileNameDes); } }; #endif
1 2 3 4 5 6 #include "encryptfacade.h" int main () unique_ptr<EncryptFacade> ef = make_unique <EncryptFacade>(); ef->FileEncrypt ("./file.txt" , "./code.txt" ); }
1 2 3 4 读取文件,获取明文。(19060212119ChenggongXing) 数据加密,将明文转换为密文! NVMSMNONNV`a^C``DC`QbC` 保存密码,写入文件。
发现,目录下多了一个code.txt,里面存放的是密文。
在标准的外观模式结构图中,如果需要增加、删除或更换与外观类交互的子系统类,必须修改外观类或客户端的源代码,这将违背开闭原则,因此可以通过引入抽象外观类来对系统进行改进,在一定程度上可以解决该问题。
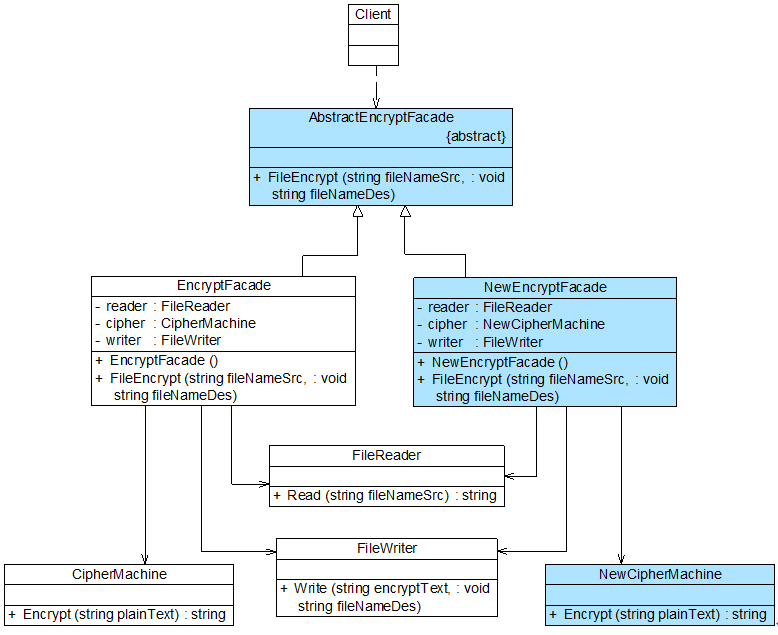
在引入抽象外观类之后,客户端可以针对抽象外观类进行编程,对于新的业务需求,不需要修改原有外观类 ,而是增加一个新的具体外观类 ,由新的具体外观类来关联新的子系统对象,同时通过修改配置文件来达到不修改任何源代码并更换外观类 的目的。
下面通过一个具体实例来学习如何使用抽象外观类:如果在应用实例“文件加密模块”中需要更换一个加密类,不再使用原有的基于求模运算的加密类CipherMachine,而改为新加密类NewCipherMachine,其代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #ifndef NEWCIPHERMACHINE_H #define NEWCIPHERMACHINE_H #include <iostream> #include <string> #include <vector> using namespace std;class NewCipherMachine { public : string Encrypt (const string & plainText) { cout << "数据加密,将明文转换为密文!" << endl; string es = "" ; vector<char > vc (plainText.begin(), plainText.end()) ; for (auto & c : vc) { es += (c % 36 ) + 60 ; } cout << es << endl; return es; } }; #endif
如果不增加新的外观类,只能通过修改原有外观类EncryptFacade的源代码来实现加密类的更换,将原有的对CipherMachine类型对象的引用改为对NewCipherMachine类型对象的引用,这违背了开闭原则,因此需要通过增加新的外观类来实现对子系统对象引用的改变。
如果增加一个新的外观类NewEncryptFacade来与FileReader类、FileWriter类以及新增加的NewCipherMachine类进行交互,虽然原有系统类库无须做任何修改,但是因为客户端代码中原来针对EncryptFacade类进行编程,现在需要改为NewEncryptFacade类,因此需要修改客户端源代码。
如何在不修改客户端代码的前提下使用新的外观类呢?
解决方法之一是:引入一个抽象外观类,客户端针对抽象外观类编程,而在运行时再确定具体外观类,引入抽象外观类之后的文件加密模块结构图如图所示:
抽象外观类AbstractEncryptFacade
1 2 3 4 5 6 7 8 #ifndef ABSTRACTENCRYPTFACADE_H #define ABSTRACTENCRYPTFACADE_H class AbstractEncryptFacade { public : virtual void FileEncrypt (const string & fileNameSrc, const string & fileNameDes) 0 ; }; #endif
新增具体加密外观类NewEncryptFacade代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #ifndef NEWENCRYPTFACADE_H #define NEWENCRYPTFACADE_H #include "abstractencryptfacade.h" #include "newciphermachine.h" #include "filereader.h" #include "filewriter.h" #include <memory> class NewEncryptFacade : public AbstractEncryptFacade{ private : shared_ptr<FileReader> reader; shared_ptr<FileWriter> writer; shared_ptr<NewCipherMachine> cipher; public : NewEncryptFacade () { reader = make_shared <FileReader>(); cipher = make_shared <NewCipherMachine>(); writer = make_shared <FileWriter>(); } void FileEncrypt (const string & fileNameSrc, const string & fileNameDes) { string plainStr = reader->Read (fileNameSrc); string encryptStr = cipher->Encrypt (plainStr); writer->Write (encryptStr, fileNameDes); } }; #endif
我们的配置文件使用json来处理,引入一个适用于cpp的json第三方库,使用json.hpp。
还需要写对应配套的map映射生成具体使用的对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #ifndef PUBLIC_H #define PUBLIC_H #include <unordered_map> #include <string> #include "abstractencryptfacade.h" #include "encryptfacade.h" #include "newencryptfacade.h" #include "functional" using namespace std;unordered_map<string, function<unique_ptr<AbstractEncryptFacade>()>> s_facade_map = { { "old" , []()->unique_ptr<AbstractEncryptFacade> {return make_unique <EncryptFacade>();}}, { "new" , []()->unique_ptr<AbstractEncryptFacade> {return make_unique <NewEncryptFacade>();}} }; #endif
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include "encryptfacade.h" #include "json.hpp" #include "public.h" #include <fstream> using json = nlohmann::json;int main () json j; ifstream jfile ("../config.json" ) ; jfile >> j; jfile.close (); unique_ptr<AbstractEncryptFacade> ef = s_facade_map[j.at ("cipher" )](); ef->FileEncrypt ("../file.txt" , "../code.txt" ); }
1 2 3 4 读取文件,获取明文。 数据加密,将明文转换为密文! IQHNHIJIIQ[\Y>[[?>[L]>[ 保存密码,写入文件。
原有外观类EncryptFacade也需作为抽象外观类AbstractEncryptFacade类的子类,更换具体外观类时只需修改配置文件,无须修改源代码,符合开闭原则。
外观模式是一种使用频率非常高的设计模式,它通过引入一个外观角色来简化客户端与子系统之间的交互,为复杂的子系统调用提供一个统一的入口,使子系统与客户端的耦合度降低,且客户端调用非常方便。外观模式并不给系统增加任何新功能,它仅仅是简化调用接口。
在几乎所有的软件中都能够找到外观模式的应用,如绝大多数B/S系统都有一个首页或者导航页面,大部分C/S系统都提供了菜单或者工具栏,在这里,首页和导航页面就是B/S系统的外观角色,而菜单和工具栏就是C/S系统的外观角色,通过它们用户可以快速访问子系统,降低了系统的复杂程度。所有涉及到与多个业务对象交互的场景都可以考虑使用外观模式进行重构。
它对客户端屏蔽了子系统组件,减少了客户端所需处理的对象数目,并使得子系统使用起来更加容易。通过引入外观模式,客户端代码将变得很简单,与之关联的对象也很少。
它实现了子系统与客户端之间的松耦合关系,这使得子系统的变化不会影响到调用它的客户端,只需要调整外观类即可。
一个子系统的修改对其他子系统没有任何影响,而且子系统内部变化也不会影响到外观对象。
不能很好地限制客户端直接使用子系统类,如果对客户端访问子系统类做太多的限制则减少了可变性和灵活性。
如果设计不当,增加新的子系统可能需要修改外观类的源代码,违背了开闭原则。
在以下情况下可以考虑使用外观模式:
当要为访问一系列复杂的子系统提供一个简单入口时可以使用外观模式。
客户端程序与多个子系统之间存在很大的依赖性。引入外观类可以将子系统与客户端解耦,从而提高子系统的独立性和可移植性。
在层次化结构中,可以使用外观模式定义系统中每一层的入口,层与层之间不直接产生联系,而通过外观类建立联系,降低层之间的耦合度。