内容
- 基本概念
- epoll
epoll
epoll是Linux特有的I/O复用函数。
epoll的使用实际上不是单独的API,而是有一组函数来完成。三个函数。
API
1 |
|
- epoll_create():创建内核事件表,存放描述符和事件,红黑树。
- epoll_ctl():添加、移除描述符,每个描述符只需要添加一次。
- epoll_wait():获取已就绪的描述符,复杂度
O(1)
内核怎么样实现O(1)?:注册回调函数的方式
epoll_create
epoll把用户关心的文件描述符上的事件放在内核里的一个事件表中,从而无须像select和poll那样每次调用都要重复传描述符集或事件集。
但epoll需要使用一个额外的文件描述符,来唯一标识内核中的这个事件表。
这个文件描述符就是使用epoll_create函数来创建。
1 | int epoll_create(int size); |
只有一个参数size,但是实际上这个参数并不起作用,只是给内核一个提示,告诉他事件表大概需要多大。
函数返回值为对应这个事件表的一个文件描述符。其他所有epoll系统调用的第一个参数将使用该返回值,以指定要访问的内核事件表。
epoll_ctl
1 | int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); |
-
参数
epfd是epoll_create返回值。 -
参数
op指定操作类型。操作类型有如下3种:EPOLL_CTL_ADD,往事件表中注册fd上的事件;EPOLL_CTL_MOD,修改fd上的注册事件;EPOLL_CTL_DEL,删除fd上的注册事件;
-
参数
fd是要操作的文件描述符 -
参数
event指定事件,它是epoll_event结构指针类型-
epoll_event的定义如下1
2
3
4
5struct epoll_event
{
__uint32_t events; /* epoll事件, 和poll类似,前加E*/
epoll_data_t data; /* 用户数据 */
}-
结构体中成员
events描述事件类型。epoll支持的事件类型与poll基本相同。表示epoll事件类型的宏是在poll对应的宏前加上"E",比如数据可读事件是EPOLLIN。但epoll有两个额外的事件类型——EPOLLET和EPOLLONESHOT,这俩事件往往对应epoll的高效运作模式。 -
data成员用于存储用户数据。其类型
epoll_data_t的定义如下:1
2
3
4
5
6
7typedef union epoll_data
{
void * ptr;
int fd;
uint32_t u32;
uint64_t u64;
}epoll_data_t;epoll_data_t是一个联合体,其4个成员中:- 使用最多的是
fd,它指定事件所从属的目标文件描述符。 - 成员
ptr可用来指定与fd相关的用户数据。但由于epoll_data_t是一个联合体,不可同时使用ptr和fd,因此,如果要将文件描述符和用户数据关联起来以实现快速的数据访问的话,只能使用其他手段。比如放弃使用fd成员,而在ptr指向的用户数据中包含fd。
- 使用最多的是
-
-
epoll_wait
在一段超时时间内等待一组文件描述符上的事件。
1 | int epoll_wait(int epfd, struct epoll_event* events, int maxevents, int timeout); |
epoll_wait函数如果检测到事件,就将所有就绪的事件从内核事件表(由epfd参数指出)中复制到它的第二个参数events指向的数组中。这个数组只用于用户接收内核检测到的就绪事件,而不像select/poll的数组参数那样拷贝来拷贝去。极大地提高了应用程序索引就绪文件描述符的效率。
参数maxevents指定最多监听多少个事件,必须大于0。
参数timeout含义与poll接口的timeout参数相同,都是指定超时值,单位是毫秒。当设置为-1时,poll调用讲永远阻塞直到某个事件发生;当设置为0时poll调用将立即返回。
与poll的代码差异
1 | int ret = poll(fds, MAX_EVENT_NUMBER, -1); |
内核事件表
epoll的最大优势在于处理描述符特别多的情况,相比轮询方式:
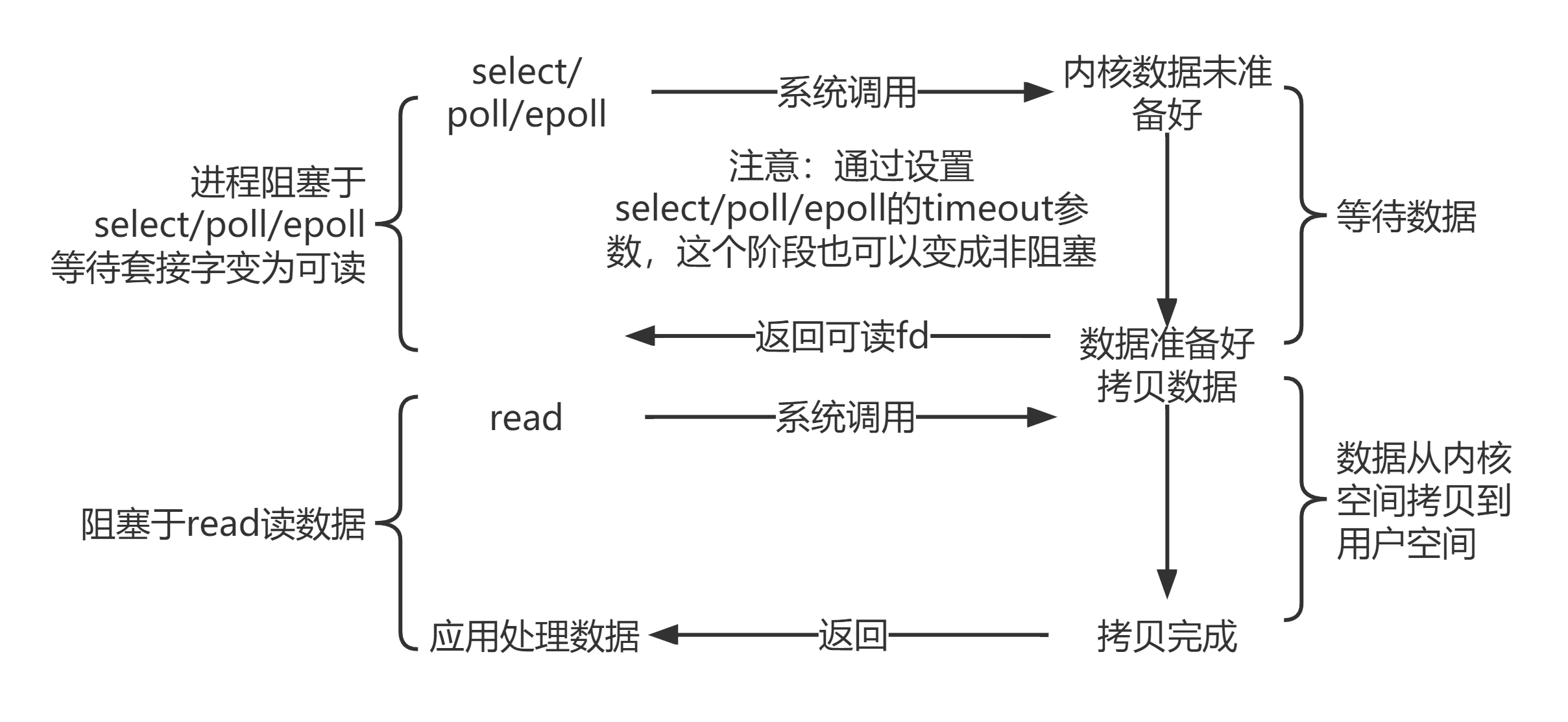
- 如果用传统的select、poll单纯的顺序轮询方法监测就绪的描述符,那么性能会很低下的。
- 而且虽然select、poll能顺利查出有几个描述符上有事件产生,但是是哪个描述符?并没有告诉我们,所以又得浪费一轮时间来查找产生时间是哪个描述符。
数据结构
本质上,是一棵红黑树。
思路的转变
相较于select/poll,我们所关心的事件(描述符)表,直接创建于内核态。
LT/ET模式
epoll对文件描述符的操作有两种模式:LT (Level Trigger, 电平触发)模式和ET (Edge Trigger, 边沿触发)模式。
- LT:有事件就绪后,用户不用立即处理;用户如果没有处理完,还会继续提醒
- ET:有事件就绪,只提醒用户一次。下次就没了。
LT
LT模式是默认的工作模式,这种模式下epoll相当于一个效率较高的poll。
对于采用LT工作模式的文件描述符,当epoll_wait检测到其上有事件发生并将此事件通知应用程序后,应用程序可以不立即处理该事件。这样,当应用程序下一次调用epoll_wait时,epoll_wait还会再次向应用程序通告此事件,直到该事件被处理。
ET
当往epoll内核事件表中注册一个文件描述符上的EPOLLET事件时,epoll将以ET模式来操作该文件描述符。ET模式是epoll的高效工作模式。
而对于采用ET工作模式的文件描述符,当epoll_wait检测到其上有事件发生并将此事件通知应用程序后,应用程序必须立即处理该事件,因为后续的epoll_wait调用将不再向应用程序通知这一事件。可见,ET模式在很大程度上降低了同一个epoll事件被重复触发的次数,因此效率要比LT模式高。
LT - 代码示例
1 |
|
ET - 代码示例
主要解决的问题:怎么一次性把描述符上的数据接收完?
-
描述符设置成非阻塞
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
int fcntl(int fd, int cmd, ... /* arg */);
/* fcntl()可以采用可选的第三个参数。是否需要这个参数由 cmd 决定。
所需的参数类型在每个 cmd 名称后面的括号中指示(在大多数情况下,所需的类型是 int,我们使用名称 arg 来标识参数),如果不需要参数,则指定 void。
只有特定的 Linux 内核版本才支持某些 cmd 操作。检查主机内核是否支持特定操作的首选方法是使用所需的 cmd 值调用 fcntl(),然后测试调用是否以 EINVAL 失败,表明内核无法识别该值。*/
/*
For a successful call, the return value depends on the operation:
F_DUPFD The new file descriptor.
F_GETFD Value of file descriptor flags.
F_GETFL Value of file status flags.
F_GETSIG Value of signal sent when read or write becomes possible, or zero for traditional SIGIO behavior.
All other commands : Zero.
On error, -1 is returned, and errno is set appropriately.
*/
可选的cmd操作(其中之二):
F_GETFL(void)//get file access mode and the file status flags
F_SETFL(int)//set file status flags to the value by arg. File access mode and file creation flags in arg are ignored. On Linux, this command can only change the O_APPEND, O_ASYNC, O_DIRECT, O_NOATIME, O_NONBLOCK flags. It's not possible to change the O_DSYNC, O_SYNC flags. -
循环处理(读取)
需要判断recv返回值为-1时的错误类型(没数据时,非阻塞情况下立即返回-1)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30返回值
如果发生错误,则返回-1,设置errno以指示错误。
当流套接字对等点执行了有序关闭时,返回值将为0(传统的“文件结束”返回)。
成功则返回接收到的字节数;
各种域(例如,UNIX 和 Internet 域)中的数据报套接字允许零长度数据报。当接收到这样的数据报时,返回值为 0。
如果从流套接字接收的请求字节数为 0,则也可能返回值 0。
错误
这些是套接字层产生的一些标准错误。底层协议模块可能会产生和返回额外的错误;查看他们的手册页。
EAGAIN 或 EWOULDBLOCK
套接字被标记为非阻塞并且接收操作将阻塞,或者已设置接收超时并且在接收数据之前超时已过期。POSIX.1允许在这种情况下返回任一错误,并且不要求这些常量具有相同的值,因此可移植应用程序应检查这两种可能性。
EBADF
参数 sockfd 是无效的文件描述符。
ECONNREFUSED
远程主机拒绝允许网络连接(通常是因为它没有运行请求的服务)。
EFAULT
接收缓冲区指针指向进程地址空间之外。
EINTR
在任何数据可用之前,接收被信号传递中断;见signal(7)。
EINVAL
传递了无效的参数。
ENOMEM
无法为 recvmsg() 分配内存。
ENOTCONN
套接字与面向连接的协议相关联,并且尚未连接(请参阅connect(2)和 accept(2))
ENOTSOCK
文件描述符 sockfd 不引用套接字。
- 设置为非阻塞
1 | void setnonblock(int fd) |
- 循环处理
1 |
|