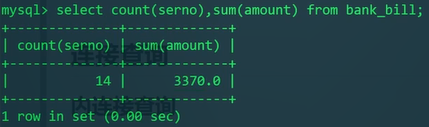
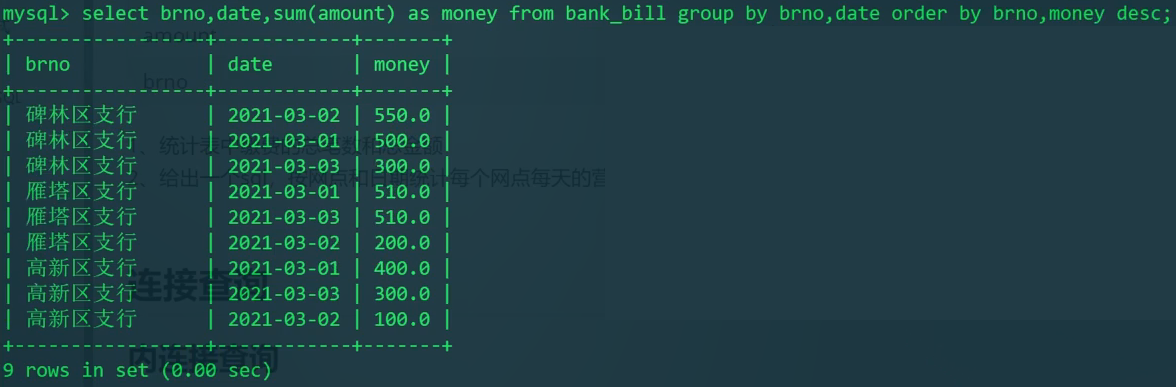
内容
安装nginx及其依赖。
可能需要的命令:
- Linux下
*.tar.gz文件解压缩命令:tar -zxvf 压缩文件名.tar.gz chown -R: 处理指定目录以及其子目录下的所有文件
参考文章
- Hexo部署至服务器(Ubuntu 20.04)
- ubuntu nginx源代码安装
- Ubuntu20.04安装openssl-1.1.1k
- linux中ln -s 命令详解
- 解决:Linux8整合Nginx过程中报错:src/os/unix/ngx_user.c: 在函数‘ngx_libc_crypt’中: src/os/unix/ngx_user.c:36:7
- OpenSSL library is not used
- 设置Nginx在linux服务器(Ubuntu)开机启动
- Unable to locate package sysv-rc-conf
- https://blog.csdn.net/weixin_45837693/article/details/107675339
安装其依赖
nginx依赖pcre、openssl、zlib
安装pcre
1 | sudo apt install libpcre3 libpcre3-dev |
安装zlib
下载地址:http://www.zlib.net
1 | tar -xvf zlib-<version>.tar.gz |