1 2 3 4 阶乘可递归地定义为: fac(n) = 1; 当n=1时 fac(n-1)*n; 当n>1时
此处, fac(n-1)代表什么意思呢? 是: 1 * 2 * ... * (n-1)
非递归版
1 2 3 4 5 6 7 8 9 int factorial (int n) { int res = 1 ; for (int i = 1 ; i <= n; ++i) { res = res * i; } return res; }
递归版
1 2 3 4 5 6 7 int factorial (int n) { if (n <= 1 ) return 1 ; else return factorial(n - 1 ) * n; }
若把上面阶乘的代码, 稍做改动:
for循环中间的条件去掉 - 变为死循环
1 2 3 4 5 6 7 8 9 int factorial (int n) { int res = 1 ; for (int i = 1 ; ; ++i) { res = res * i; } return res; }
但是, 死循环除了会耗费单核的CPU, 不会对内存空间产生伤害;
1 2 3 4 int main () { int sum = fun(4 ); }
若把上面递归版本阶乘的代码, 稍做改动, 把if判断条件改为永假:
1 2 3 4 5 6 7 int factorial (int n) { if (false ) return 1 ; else return factorial(n - 1 ) * n; }
则递归将没有一个出口;
而且更严重的是, 由于每一次的递归调用都需要开辟栈帧, 所以不久之后栈将会溢出, 程序崩溃;
就这个现象, 其实说明了背后的一些更重要的意义, 一般, 非递归算法的空间复杂度最低可为O(1), 而递归算法的空间复杂度最低为O(n), 递归的特性势必造成额外的空间;
假如有一int数组为{12,23,34}, 要求打印出来
1 2 3 4 5 6 7 8 9 void Print_Ar (const int * ar, int n) assert (ar != NULL ); for (int i = 0 ; i < n; ++i) { cout << ar[i] << " " ; } cout << endl; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 void Print (const int * ar, int n) if (n > 0 ) { cout << ar[n-1 ] << " " ; Print (ar, n-1 ); } } void Print_Ar_recur (const int * ar, int n) assert (ar != NULL ); if (n < 1 ) return ; Print (ar, n); cout << endl; } int main () int ar[] = {12 , 23 , 34 }; int n = sizeof (ar) / sizeof (ar[0 ]); Print_Ar_recur (ar, n); return 0 ; }
看到没? 只是把5行和6行的代码调了个序, 效果就截然不同, 这就是递归的神奇之处;
当n > 0时, 将一直递归下去, 直到n等于0, 之后, 随着递归栈帧的回退, 将从0到n-1逐一打印出来;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 void Print (const int * ar, int n) if (n > 0 ) { Print (ar, n - 1 ); cout << ar[n-1 ] << " " ; } } void Print_Ar_recur (const int * ar, int n) assert (ar != NULL ); if (n < 1 ) return ; Print (ar, n); cout << endl; } int main () int ar[] = {12 , 23 , 34 }; int n = sizeof (ar) / sizeof (ar[0 ]); Print_Ar_recur (ar, n); return 0 ; }
递归的题解有两部分组成, 将会把代码划分的清清楚楚;
第一个函数过滤掉不合法的参数, 同时作为开始调用递归的调用者;
第二个函数才是真正的递归函数;
递归函数的执行分为“递推”和“回归”两个过程,这两个过程由递归终止条件控制,即逐层递推,直至递归终止条件满足,终止递归,然后逐层回归。
递归调用同普通的函数调用一样,每当调用发生时,就要分配新的栈帧 (形参数据,现场保护,局部变量), 所以, 每个栈帧中的数据都是本层独有的! ;
而与普通的函数调用不同的是,由于递推的过程是一个逐层调用的过程,因此存在一个逐层连续的分配栈帧过程,直至遇到递归终止条件时,才开始回归,这时才逐层释放栈帧空间,返回到上一层,直至最后返回到主调函数。
这个浅看看不出来, 实际上是一个必死的结局;
这个会导致栈溢出 ;
因为, n--会导致每次前一个栈帧给下一个函数传递的是n原本的值, 才去--, 这是后置自减的语义, 然后, 就相当于n原地不变, 所以一直到不了栈帧回退的出口;
1 2 3 4 5 6 7 8 void Print (const int * br, int n) { if (n > 0 ) { Print(br, n--); cout << br[n - 1 ] << " " ; } }
会导致越界, 并且前面多打了一个(br[-1]), 后面少打了一个(br[n-1]);
因为他把n减1并传过去了, 就缺少了n的情况, 并且, 由于前面做了n值的判断, 而又在if里面改值, 这是不妥的; 即, 最好不要在判断n的合法性后对n进行改动, 这是递归程序的忌讳;
1 2 3 4 5 6 7 8 void Print (const int * br, int n) { if (n > 0 ) { Print(br, --n); cout << br[n - 1 ] << " " ; } }
但是这种情况, 也可以把程序改正确, 即: 把打印br[n-1]改为br[n]
1 2 3 4 5 6 7 8 void Print (const int * br, int n) { if (n > 0 ) { Print(br, --n); cout << br[n] << " " ; } }
但还是不建议在递归程序的变量上进行前置自减;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void Print (const int * br, int & n) if (n > 0 ) { Print (br, --n); cout << br[n] << " " ; } } void Print_Ar_recur (const int * br, int n) assert (br != NULL ); if (n < 1 )return ; Print (br, n); cout << endl; }
因为栈帧递进时, 所有栈帧中的n都一直在动态改变, 最终所有栈帧的n值都变为0了, 即所有的n都保持一致了 , 因此, 打印的都是br[0], 这是引用的影响;
尽量在递归中少用引用,只有在线索二叉树才会用到
传入数据指针, 长度, 和要找到val值, 返回下标
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int FindPos (const int * br, int n, int val) if (br == NULL || n < 1 )return -1 ; int pos = n - 1 ; while (pos >= 0 && br[pos]!=val) { --pos; } return pos; } int main () int ar[] = {12 ,56 ,34 ,78 }; int n = sizeof (ar)/sizeof (ar[0 ]); int val = 78 ; int pos = FindPos (ar,n,val); cout << pos << endl; }
1 2 3 4 5 6 7 8 9 10 11 12 13 int Find (const int * br, int n, int val) if (n > 0 ) { if (br[n - 1 ] == val) return n - 1 ; return Find (br, n - 1 , val); } } int FindPos (const int * br, int n, int val) if (br == NULL || n < 1 ) return -1 ; return Find (br, n, val); }
错误点:如果没有找到val,没有返回值。即, 如果走到n==-1, 则没有return的值, 可视为获取到了一个随机值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int Find (const int * br, int n, int val) if (n <= 0 || br[n-1 ] == val) { return n - 1 ; } else { return Find (br, n - 1 , val); } } int FindPos (const int * br, int n, int val) if (br==NULL || n<1 )return -1 ; return Find (br,n,val); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int Find (const int * br, int n, int val) { if (n > 0 ) { if (br[n-1 ] == val) return n - 1 ; else return Find(br, n - 1 , val); } return -1 ; } int FindPos (const int * br, int n, int val) { if (br==NULL || n < 1 )return -1 ; return Find(br, n, val); }
快排、归并、堆排
时间复杂度是多少?
空间复杂度是多少?
是否稳定?怎样可以稳定?什么时候需要稳定,什么时候不需要稳定?
什么情况下性能会退化?
三个排序的适用场景?
如果你的排序的递归的,怎么改为非递归?
为什么数据有序的时候, 快排时间复杂度为O ( n 2 ) O(n^2) O ( n 2 )
这个仅限于每次只从最边缘数据作为划分, 才出现这种情况
每次划分时, 相当于只划分出了一个数据和剩余的数据, 规模并没有有效的减小, 仍需要划分n n n log 2 n \log_2n log 2 n
放在二叉树上的形象图示就是: 最差情况下的快排就是一个极端不平衡的二叉树, 最好情况下的快排就是一个很平衡的二叉树;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int Partition (int *ar, int left, int right) int tmp = ar[left]; while (left < right) { while (left < right && ar[right] > tmp) { --right; } if (left < right) ar[left] = ar[right]; while (left < right && ar[right] <= tmp) { ++left; } if (left < right) ar[right] = ar[left]; } ar[left] = tmp; return left; }
left < right?
因为, 如果不加这种条件的话, left或right可能就会一直贪婪地, 不着边际地走下去, 最终left和right有可能错位 !
如果产生了错位, left的right下标的值相互赋值将没有意义;
反之, 如果很好地控制了left和right的位置, 最终退出整个while循环后, left和right的位置一定指向的是同一个位置; 即, 最后两句的ar[left] = tmp和return left同样可以换为ar[right] = tmp和return left!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void PassQuick (int *ar, int left, int right) { if (left < right) { int pos = Partition(ar, left, right); PassQuick(ar, left, pos - 1 ); PassQuick(ar, pos + 1 , right); } } void QuickSort (int * ar, int n) { if (ar == NULL || n < 2 )return ; PassQuick(ar, 0 , n-1 ); }
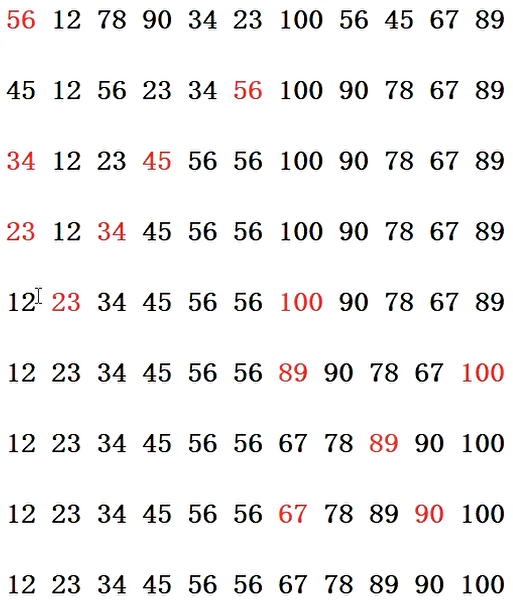
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void Print_Ar (const int * ar, int n) { if (ar == NULL || n < 1 )return ; for (int i = 0 ; i < n; ++i) { cout << ar[i] << " " ; } cout << endl ; } int main () { int ar[] = {56 , 12 , 78 , 90 , 34 , 23 , 100 , 56 , 45 , 67 , 89 }; int n = sizeof (ar) / sizeof (ar[0 ]); Print_Ar(ar, n); QuickSort(ar, n); Print_Ar(ar, n); }
同时, 也可以在PassQuick函数中Partition语句的下一行加个Print_Ar(ar, 11); 这样就能在每次划分完毕之后, 清楚地看到数组的状态;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 void QuickSort (int * ar, int n) if (ar == NULL || n < 2 ) return ; queue<int > qu; qu.push (0 ); qu.push (n - 1 ); while (!qu.empty ()) { int left = qu.front (); qu.pop (); int right = qu.front (); qu.pop (); int pos = Partition (ar, left, right); if (left < pos - 1 ) { qu.push (left); qu.push (pos - 1 ); } if (pos + 1 < right) { qu.push (pos + 1 ); qu.push (right); } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void QuickSort (int * ar, int n) if (ar == NULL || n < 2 ) return ; queue<std::pair<int , int >> qu; qu.push (std::pair <int , int >(0 , n-1 )); while (!qu.empty ()) { std::pair<int , int > record = qu.front (); qu.pop (); int pos = Partition (ar, record.first, record.second); if (record.first < pos - 1 ) { qu.push (std::pair <int , int >(record.first, pos-1 )); } if (pos + 1 < record.second) { qu.push (std::pair <int , int >(pos+1 , record.second)); } } }
可以使用别名使程序简化 - using idxPair = std::pair<int, int>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void QuickSort (int * ar, int n) if (ar == NULL || n < 2 ) return ; using idxPair = std::pair<int , int >; queue<idxPair> qu; qu.push (idxPair (0 , n-1 )); while (!qu.empty ()) { idxPair record = qu.front (); qu.pop (); int pos = Partition (ar, record.first, record.second); if (record.first < pos - 1 ) { qu.push (idxPair (record.first, pos-1 )); } if (pos + 1 < record.second) { qu.push (idxPair (pos+1 , record.second)); } } }
详见 “快速排序” 一文;
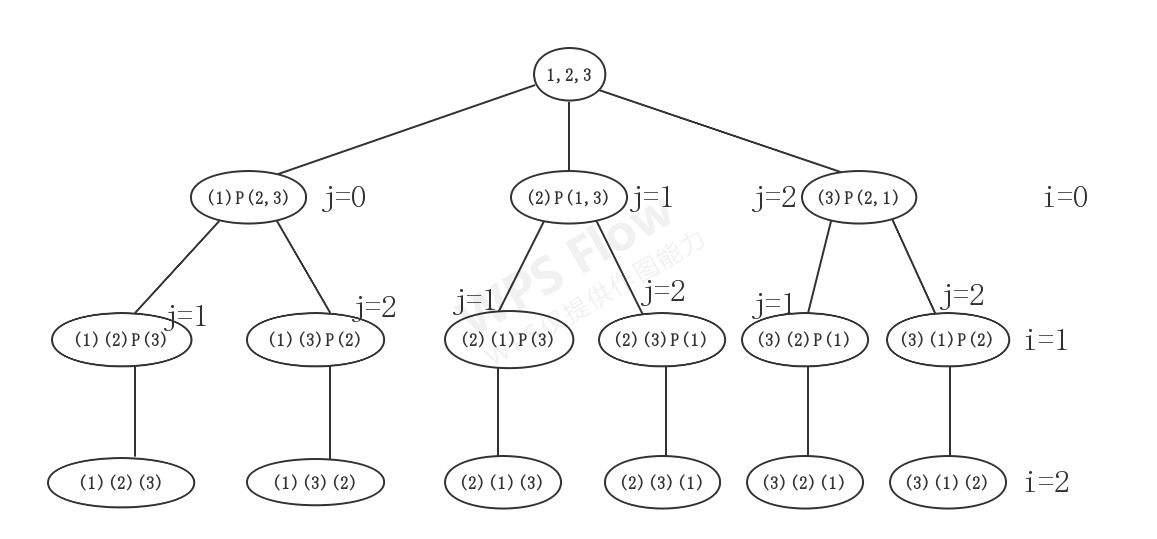
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 void Perm (int * ar, int i, int m) if (i == m) { for (int j = 0 ;j <= m;++j) { cout << ar[j] << " " ; } cout << endl; } else { for (int j = i;j <= m;++j) { std::swap (ar[i],ar[j]); Perm (ar,i+1 ,m); std::swap (ar[i],ar[j]); } } } int main () int ar[] = {1 ,2 ,3 }; int n = sizeof (ar)/sizeof (ar[0 ]); Perm (ar, 0 , n-1 ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 void fun (int i, int n) if (i >= n)return ; else { fun (i+1 , n); fun (i+1 , n); } } void Print (int *ar, int * br, int i, int n) if (i >= n) { for (int j = 0 ;j < n;++j) { if (br[j] == 1 ) { cout << ar[j] << " " ; } cout << endl; } } else { br[i] = 1 ; Print (ar, br, i+1 , n); br[i] = 0 ; Print (ar, br, i+1 , n); } } int main () int ar[] = {1 ,2 ,3 }; int br[] = {0 ,0 ,0 }; Print (ar, br, 0 , 3 ); return 0 ; }